推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2708 天前的主题,其中的信息可能已经有所发展或是发生改变。
我想先从第一个生成器取第 1 个值,从第二个生成器取第 1 个值,从第三个生成器取第 1 个值
接下来从第一个生成器取第 2 个值,从第二个生成器取第 2 个值,从第三个生成器取第 2 个值
以此类推,
最后从第一个生成器取第 5 个值,从第二个生成器取第 5 个值,从第三个生成器取第 5 个值
a = (x for x in range(1, 6))
b = (x for x in range(6, 11))
c = (x for x in range(11, 16))
d = (x for x in [a, b, c])
def y():
for m in d:
yield next(m)
for i in y():
print(i)
我想实现的输出为:
1
6
11
2
7
12
3
8
13
4
9
14
5
10
15
但是,上面的代码由于生成器只能被完整迭代一次所以在 for m in d:这个位置就会出问题。最后只能得到 1, 6, 11
请问有什么比较好的办法解决实现这个需求吗?
这个问题,是为了实现逐行对比超大 Log。我想一行一行对比 Log,但是由于三个 Log 各自都超过了 40G,因此想通过生成器的这种方式来实现。
第 1 条附言 · 2017-08-24 21:11:41 +08:00
总结一下,楼下目前主要有两种方案,一种是使用 iter 让生成器变得可迭代,另一种方案是使用 zip 把多个生成器包起来。
我个人倾向于使用 iter 来处理。
我个人倾向于使用 iter 来处理。
 |
1
wwqgtxx 2017-08-24 16:47:15 +08:00 via iPhone
a = range(1,6)
b = range(6,11) c = range(11,16) def y(): ----while True: --------yield a.__next__() --------yield b.__next__() --------yield c.__next__() for i in y(): ----print(i) |
 |
2
billion OP 可以正常运行,非常感谢。
|
|
3
billion OP @wwqgtxx 但如果有非常多的文件呢,比如有一万个文件,那在 while True 没有办法分别单独 yield xxx.__next__()了。此时又怎么办?
|
 |
4
fanhaipeng0403 2017-08-24 16:58:26 +08:00
In [21]: a = iter(range(1,6))
...: b = iter(range(6,11)) ...: c = iter(range(11,16)) ...: ...: ...: ...: In [22]: def y(): ...: while 1: ...: yield next(a) ...: yield next(b) ...: yield next(c) ...: In [23]: In [23]: for i in y(): ...: print(i) ...: 1 6 11 2 7 12 3 8 13 4 9 14 5 10 15 |
|
5
wwqgtxx 2017-08-24 16:59:24 +08:00
>>> a = range(1,6)
>>> b = range(6,11) >>> c = range(11,16) >>> >>> d = [a.__iter__(),b.__iter__(),c.__iter__()] >>> >>> def y(): ... while True: ... for m in d: ... yield next(m) ... >>> for i in y(): ... print(i) ... |
|
6
fanhaipeng0403 2017-08-24 16:59:59 +08:00
为什么我的显示 -。-AttributeError: 'range' object has no attribute '__next__'
|
|
7
wwqgtxx 2017-08-24 17:00:30 +08:00
a = range(1,6)
b = range(6,11) c = range(11,16) d = [iter(a),iter(b),iter(c)] def y(): ----while True: --------for m in d: ------------yield next(m) for i in y(): ----print(i) |
 |
8
GeruzoniAnsasu 2017-08-24 17:00:46 +08:00
➜ /tmp python3
Python 3.5.2 (default, Nov 17 2016, 17:05:23) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> ia = ( x for x in range (10) ) >>> ib = ( x for x in range(10) ) >>> ii = zip(ia,ib) >>> for a,b in ii: ... print(a,b) ... 0 0 1 1 python3 里的 zip 出来的结果本身就是一个迭代器了 |
|
9
wwqgtxx 2017-08-24 17:04:00 +08:00
@fanhaipeng0403 因为我忘记先调用 iter()了
|
|
10
wwqgtxx 2017-08-24 17:06:50 +08:00
@GeruzoniAnsasu 其实你这段代码的前两行并不用把 range 对象转换成 tuple 的,直接 zip()即可,这样能大幅度减少内存占用
|
|
11
wwqgtxx 2017-08-24 17:08:23 +08:00
>>> ii = zip(range(1,6),range(6,11),range(11,16))
>>> i = iter(ii) >>> next(i) (1, 6, 11) >>> next(i) (2, 7, 12) >>> next(i) (3, 8, 13) >>> next(i) (4, 9, 14) >>> next(i) (5, 10, 15) >>> next(i) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration |
|
12
GeruzoniAnsasu 2017-08-24 17:09:27 +08:00
@wwqgtxx 不会转成 tuple,python3 里这个看似 tuple 的东西还是个迭代器。。
|
 |
13
ferstar 2017-08-24 17:11:08 +08:00
换个思路, 像这样:
--- f1 = 'file1' f2 = 'file2' f3 = 'file3' def do_sth(l1, l2, l3): ....pass with open(f1, 'r') as fh1, open(f2, 'r') as fh2, open(f3, 'r') as fh3: ....while True: ........ f1_line = fh1.readline() ........f2_line = fh2.readline() ........f3_line = fh3.readline() ........do_sth(f1_line, f2_line, f3_line) ........if not f1_line or not f2_line or not f3_line: ............break |
|
14
GeruzoniAnsasu 2017-08-24 17:11:17 +08:00
>>> def getwhat():
... a = ( x for x in range(1,10)) ... b = ( x for x in range(15,24)) ... c = zip(a,b) ... for v in c: ... for vv in v: ... yield vv ... >>> [b for b in getwhat()] [1, 15, 2, 16, 3, 17, 4, 18, 5, 19, 6, 20, 7, 21, 8, 22, 9, 23] 这样可以每次只返回一个 |
|
15
wwqgtxx 2017-08-24 17:12:29 +08:00
@GeruzoniAnsasu 好吧,还真的是,不过这样两层迭代器嵌套也没啥意思。。
>>> ( x for x in range (10) ) <generator object <genexpr> at 0x000001F09127FFC0> |
|
16
wwqgtxx 2017-08-24 17:13:08 +08:00
@GeruzoniAnsasu 准确说应该是一个生成器而不是迭代器
|
 |
18
mark06 2017-08-24 17:43:14 +08:00
#!usr/bin/env python2.7
from itertools import izip a = (x for x in range(1, 6)) b = (x for x in range(6, 11)) c = (x for x in range(11, 16)) ii = izip(a, b, c) def func(): for i, (x, y, z) in enumerate(ii): yield x yield y yield z for item in func(): print item --- izip 返回的对象是个迭代器,你看看是否合适。 |
 |
19
kkzxak47 2017-08-24 17:46:16 +08:00
|
 |
21
dsg001 2017-08-24 19:17:45 +08:00
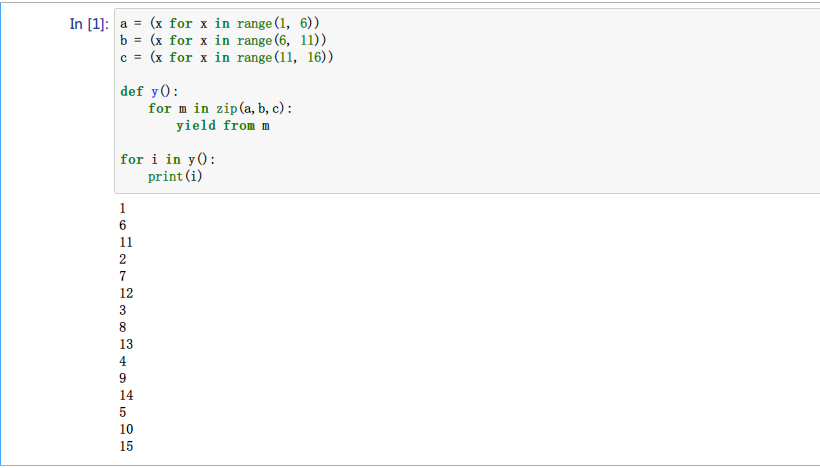
|
|
23
wwqgtxx 2017-08-24 21:49:57 +08:00
@billion 在 Py3 中如果你写成(x for x in range (10)) 则不会,如果写成[x for x in range (10)]就会
|
 |
24
NoAnyLove 2017-08-24 23:56:13 +08:00
可以用 yield from 语句
|
|
25
NoAnyLove 2017-08-25 08:11:14 +08:00
发现我在#24 楼说错了,yield from 会从生成器中挨个提取完才发挥
@billion iter 函数调用对象的__iter__()方法; generator 是 iterator 的子类,iterator 要求实现__iter__()方法,并返回自身。所以 iter(生成器) 实际上直接返回了生成器。 另外,在#18 的基础上,如果生成器长度不同,且生成器中没有 None,可以用 filter 进行处理: ```python3 def another_roundrobin(*iterables): for i in itertools.zip_longest(*iterables, fillvalue=None): yield from filter(lambda x: x is not None, i) ``` PS:itertools 文档中,Itertools Recipes 章节的 roundrobin 函数写得非常巧妙 |