推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

[不分词版]Chinese-Text-Classification: Tensorflow CNN 模型实现的中文文本分类器
1722332572 · 2017-11-10 12:50:37 +08:00 · 3417 次点击这是一个创建于 2879 天前的主题,其中的信息可能已经有所发展或是发生改变。
从现在的结果来看,分词的版本( https://www.v2ex.com/t/404977#reply6 )准确率稍微高一点。
项目地址: https://github.com/fendouai/Chinese-Text-Classification
jieba 分词的版本在 master 分支,不分词的版本在 dev 分支。
训练过程:
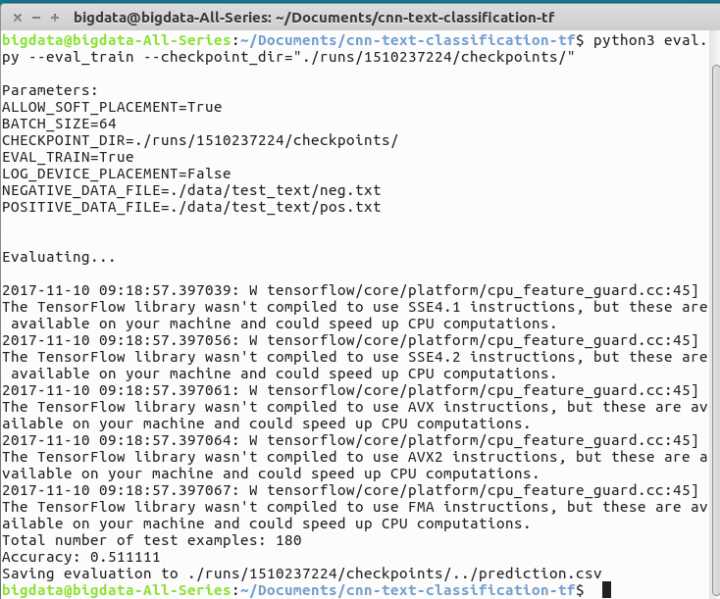
模型评估:

实验三,准备换一下数据集,用这里的数据集来跑这个模型: https://zhuanlan.zhihu.com/p/30736422
 |
1
northisland 2017-11-10 12:51:35 +08:00
很好
|
 |
2
scusjs 2017-11-10 13:37:29 +08:00
前段时间尝试过几个中文分类的模型,你可以尝试下分词后使用训练好的 word2vec,我这边测试这样的效果会好一些。
|
 |
3
1722332572 OP @scusjs 好的,谢谢。这也是准备尝试的方向。
|