
这是一个创建于 2356 天前的主题,其中的信息可能已经有所发展或是发生改变。
场景
产品表 product 有个字段叫做 shop_product_category_id 来表示 卖家设置的产品分类 id,产品也可以不设置卖家自己的分类此时分类 id 为 null,卖家会对这个产品分类添加访问密码,也可以不设置访问密码此时密码为 null,也就是表 shop_product_category 的 access_key 来存储。
业务需求
现在要查询得到没有分类访问密码限制的所有产品(没对产品分配产品分类或者已经分配分类但分类没设置密码),如图中 sql
https://i.loli.net/2018/08/09/5b6bd489b934c.png
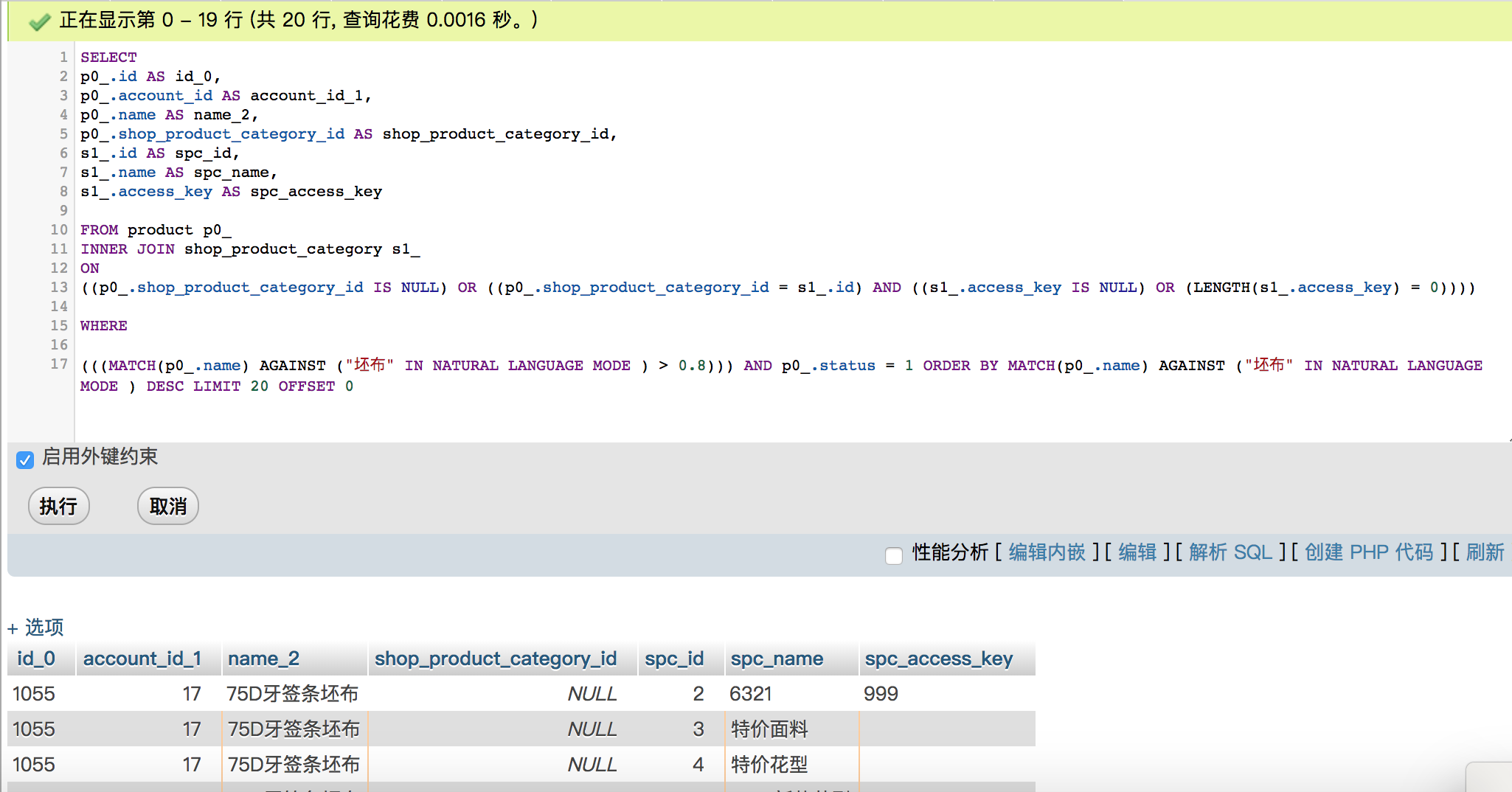{kind=link}
碰到的问题
我碰到的问题是我写的这个 sql 会重复返回同样 id 的产品,比如图中的三个 1055,这样会导致 ORM 其实认为只查询到了 1 个对象,这就导致 LIMIT 20 其实并没有查询获得 20 个不同产品,所有我想要是 sql 如何返回每行的产品 id 都不同?
图里的 sql 如下
SELECT
( p0_.id) AS id_0,
p0_.account_id AS account_id_1,
p0_.name AS name_2,
p0_.shop_product_category_id AS shop_product_category_id,
s1_.id AS spc_id,
s1_.name AS spc_name,
s1_.access_key AS spc_access_key
FROM product p0_
INNER JOIN shop_product_category s1_
ON
((p0_.shop_product_category_id IS NULL) OR ((p0_.shop_product_category_id = s1_.id) AND ((s1_.access_key IS NULL) OR (LENGTH(s1_.access_key) = 0))))
WHERE
(((MATCH(p0_.name) AGAINST ("坯布" IN NATURAL LANGUAGE MODE ) > 0.8))) AND p0_.status = 1 ORDER BY MATCH(p0_.name) AGAINST ("坯布" IN NATURAL LANGUAGE MODE ) DESC LIMIT 20 OFFSET 0
 |
1
zjsxwc OP 好像 GROUP BY 可以
``` SET session sql_mode=(SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', '')); SELECT min( p0_.id) AS id_0, p0_.account_id AS account_id_1, p0_.name AS name_2, p0_.shop_product_category_id AS shop_product_category_id, s1_.id AS spc_id, s1_.name AS spc_name, s1_.access_key AS spc_access_key FROM product p0_ INNER JOIN shop_product_category s1_ ON ((p0_.shop_product_category_id IS NULL) OR ((p0_.shop_product_category_id = s1_.id) AND ((s1_.access_key IS NULL) OR (LENGTH(s1_.access_key) = 0)))) WHERE (((MATCH(p0_.name) AGAINST ("坯布" IN NATURAL LANGUAGE MODE ) > 0.8))) AND p0_.status = 1 GROUP BY p0_.id ORDER BY MATCH(p0_.name) AGAINST ("坯布" IN NATURAL LANGUAGE MODE ) DESC LIMIT 20 OFFSET 0 ``` |
 |
2
saulshao 2018-08-09 15:20:47 +08:00
正常的做法就是 GROUP BY,你需要按什么去重,就 GROUP BY 哪(几)个字段
|
 |
3
linuxsteam 2018-08-09 15:27:07 +08:00
distinct 不太好,之前用过,不过忘记什么原因放弃使用 distinct 了。
同意楼上看法,不过 group by 不是按照最后时间或者最新时间分组的 |
 |
4
niubee1 2018-08-09 15:33:16 +08:00
先去重了再 join 子表
|