
这是一个创建于 2307 天前的主题,其中的信息可能已经有所发展或是发生改变。
流( Stream )
流是什么
流是 Java API 的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。就现在来说,你可以把它们看成遍历数据集的高级迭代器。此外,流还可以透明地并行处理,你无需写任何多线程代码了!我会在后面的笔记中详细记录和解释流和并行化是怎么工作的。我们简单看看使用流的好处吧。下面两段代码都是用来返回低热量的菜肴名称的,并按照卡路里排序,一个是用 Java7 写的,另一个是用 Java8 的流写的。比较一下。不用太担心 Java 8 代码怎么写,我们在接下来会对它进行详细的了解。
菜单筛选
使用 Java7:
private static List<String> getLowCaloricDishesNamesInJava7(List<Dish> dishes) {
List<Dish> lowCaloricDishes = new ArrayList<>();
// 遍历筛选出低于 400 卡路里的菜,添加到另外一个集合中
for (Dish d : dishes) {
if (d.getCalories() < 400) {
lowCaloricDishes.add(d);
}
}
// 对集合按照卡路里大小进行排序
List<String> lowCaloricDishesName = new ArrayList<>();
Collections.sort(lowCaloricDishes, new Comparator<Dish>() {
@Override
public int compare(Dish d1, Dish d2) {
return Integer.compare(d1.getCalories(), d2.getCalories());
}
});
// 遍历将菜名添加到另外一个集合中
for (Dish d : lowCaloricDishes) {
lowCaloricDishesName.add(d.getName());
}
return lowCaloricDishesName;
}
在上面的代码中,看起来很冗长,我们使用了一个“垃圾变量” lowCaloricDishes。它唯一的作用就是作为一次性的中间容器。 在 Java8,实现的细节被放到了它本该归属的库力了。 使用 Java8:
private static List<String> getLowCaloricDishesNamesInJava8(List<Dish> dishes) {
return dishes.stream()
// 选出 400 卡路里以下的菜肴
.filter(d -> d.getCalories() < 400)
// 按照卡路里排序
.sorted(comparing(Dish::getCalories))
// 提取菜名
.map(Dish::getName)
// 转为集合
.collect(toList());
}
太酷了!原本十几行的代码,现在只需要一行就可以搞定,这样的感觉真的是太棒了!还有一个很棒的新特性,为了利用多核架构并行执行代码,我们只需要将 stream()改为 parallelStream()即可:
private static List<String> getLowCaloricDishesNamesInJava8(List<Dish> dishes) {
return dishes
.parallelStream()
// 选出 400 卡路里以下的菜肴
.filter(d -> d.getCalories() < 400)
// 按照卡路里排序
.sorted(comparing(Dish::getCalories))
// 提取菜名
.map(Dish::getName)
// 转为集合
.collect(toList());
}
你可能会想,在调用 parallelStream 方法时到底发生了什么。用了多少个线程?对性能有多大的提升?不用着急,在后面的读书笔记中会讨论这些问题。现在,你可以看出,从软件工程师的角度来看,新的方法有几个显而易见的好处。
- 代码是以声明性的方式写的:说明想要完成什么(筛选热量低的菜肴)而不是说明如何实现一个操作(利用循环和 if 条件等控制流语句)。
- 你可以把几个基础操作链接起来,来表达复杂的数据处理流水线(在 filter 后面接上 sorted、map 和 collect 操作),同时保持代码清晰可读。filter 的结果被传给了 sorted 方法,再传给 map 方法,最后传给 collect 方法。
filter、sorted、map 和 collect 等操作是与具体线程模型无关的高层次构件,所以它们的内部实现可以是单线程的,也可能透明地充分利用你的多核架构!在实践中,这意味着我们用不着为了让某些数据处理任务并行而去操心线程和锁了,Stream API 都替你做好了!
现在就来仔细探讨一下怎么使用 Stream API。我们会用流与集合做类比,做点儿铺垫。下一 章会详细讨论可以用来表达复杂数据处理查询的流操作。我们会谈到很多模式,如筛选、切片、 查找、匹配、映射和归约,还会提供很多测验和练习来加深你的理解。接下来,我们会讨论如何创建和操纵数字流,比如生成一个偶数流,或是勾股数流。最后,我们会讨论如何从不同的源(比如文件)创建流。还会讨论如何生成一个具有无穷多元素的流,这用集合肯定是搞不定。
流简介
要讨论流,我们首先来谈谈集合,这是最容易上手的方式了。Java8 中的集合支持一个新的 stream 方法,它会返回一个流(接口定义在 java.util.stream.Stream 里)。你在后面会看到,还有很多其他的方法可以得到流,比如利用数值范围或从 I/O 资源生成流元素。
那么,流到底是什么呢?简短的定义就是“从支持数据处理操作的源生成的元素序列”。让我们一步步剖析这个定义。
- 元素序列:就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间 /空间复杂度存储和访问元素(如 ArrayList 与 LinkedList )。但流的目的在于表达计算,比如你前面见到的 filter、sorted 和 map。集合讲的是数据,流讲的是计算。
- 源:流会使用一个提供数据的源,如集合、数组或输入 /输出资源。请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
- 数据处理操作:流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如 filter、map、reduce、find、match、sort 等。流操作可以顺序执行,也可并行执行。
此外,流操作有两个重要的特点。
- 流水线:很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。
- 内部迭代:与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
让我们来看一段能够体现所有这些概念的代码:
List<Dish> menu = Dish.MENU;
// 从 menu 获得流
List<String> threeHighCaloricDishNames = menu.stream()
// 通过链式操作,筛选出高热量的菜肴
.filter(d -> d.getCalories() > 300)
// 获取菜名
.map(Dish::getName)
.limit(3)
.collect(Collectors.toList());
// [pork, beef, chicken]
System.out.println(threeHighCaloricDishNames);
看起来很简单,就算不明白也没关系,我们来了解了解,刚刚使用到的一些方法:
- filter: 接受 Lambda,从流中排除某些元素。在刚刚的代码中,通过传递 Lambda 表达式
d -> d.getCalories() > 300,选择出热量高于 300 卡路里的菜肴。 - map:接受一个 Lambda,将元素转换成其他形式或提取信息。在刚刚的代码中,通过传递方法引用
Dish::getName,提取了每道菜的菜名。 - limit:截断流,使其元素不超过给定的数量。
- collect:将流转换为其他形式。在刚刚的代码中,流被转为一个 List 集合。
在刚刚解释的这段代码,与遍历处理菜单集合的代码有很大的不同。首先,我们使用了声明性的方式来处理菜单数据。我们并没有去实现筛选( filter )、提取( map )或截断( limit )功能,Stream 库已经自带了。因此,StreamAPI 在决定如何优化这条流水线时更为灵活。例如,筛选、提取和截断操作可以一次进行,并在找到这三道菜后立即停止。
流与集合
Java 现有的集合概念和新的流概念都提供了接口,来配合代表元素型有序值的数据接口。所谓有序,就是说我们一般是按顺序取用值,而不是随机取用的。那这两者有什么区别呢?
打个比方说,我们在看电影的时候,这些视频就是一个流(字节流或帧流),流媒体视频播放器只要提前下载用户观看位置的那几帧就可以了,这样不用等到流中大部分值计算出来。比如,我们在 Youtube 上看的视频进度条随便拖动到一个位置,你会发现它很快就开始播放了,不需要将整个视频都加载好,而是加载了一段。如果,不按照这种方式的话,我们可以想象一下,视频播放器可能没有将整个流作为集合,保存所需要的内存缓冲区——而且要是非得等到最后一帧出现才能开始看,那等待的时间就太长了,早就没耐心看了。
初略地说,集合与流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值,集合中的每个元素都得先算出来才能添加到集合中。
相比之下,流则是在概念上固定的数据结构,其元素则是按需计(懒加载)算的。需要多少就给多少。这是一种生产者与消费者的关系。从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会生成值。与之相反,集合则是急切创建的(就像黄牛囤货一样)。
流只能遍历一次
请注意,和迭代器类似,流只能遍历一次。遍历完之后,我们就说这个流已经被消费掉了。你可以从原始数据源那里再获得一个新的流来重新遍历一遍,就像迭代器一样(这里假设它是集合之类的可重复的源,如果是 I/O 通道就没戏了)。例如以下代码会抛出一个异常,说流已被消费掉了:
List<String> names = Arrays.asList("Java8", "Lambdas", "In", "Action");
Stream<String> s = names.stream();
s.forEach(System.out::println);
// 再继续执行一次,则会抛出异常
s.forEach(System.out::println);
千万要记住,它只能消费一次!
外部迭代与内部迭代
使用 Collection 接口需要用用户去做迭代(比如用 for-each ),这个称为外部迭代。反之,Stream 库使用内部迭代,它帮你把迭代做了,还把得到的流值存在了某个地方,你只要给出一个函数说要干什么就可以了。下面的代码说明了这种区别。
集合:使用 for-each 循环外部迭代:
// 集合:使用 for-each 循环外部迭代
List<Dish> menu = Dish.MENU;
List<String> names = new ArrayList<>();
for (Dish dish : menu) {
names.add(dish.getName());
}
请注意,for-each 还隐藏了迭代中的一些复杂性。for-each 结构是一个语法糖,它背后的东西用 Iterator 对象表达出来更要丑陋得多。
集合:用背后的迭代器做外部迭代
List<String> names = new ArrayList<>();
Iterator<String> iterator = menu.iterator();
while(iterator.hasNext()) {
Dish d = iterator.next();
names.add(d.getName());
}
流:内部迭代
List<String> names = menu.stream()
.map(Dish::getName)
.collect(toList());
让我们用一个比喻来解释一下内部迭代的差异和好处吧!比方说你在和你两岁的儿子说话,希望他能把玩家收起来。
你:“儿子,我们把玩家收起来吧。地上还有玩具吗?”
儿子:“有,球。”
你:“好,放进盒子里。还有吗?”
儿子:“有,那是我的飞机。”
你:“好,放进盒子里。还有吗?”
儿子:“有,我的书。”
你:“好,放进盒子里。还有吗?”
儿子:“没了,没有了。”
你:“好,我们收好啦!”
这正是你每天都要对 Java 集合做的。你外部迭代一个集合,显式地取出每个项目再加以处理。如果,你对儿子说“把地上的所有玩具都放进盒子里收起来”就好了。内部迭代比较好的原因有二:第一,儿子可以选择一只手拿飞机,另一只手拿球第二,他可以决定先拿离盒子最近的那个东西,然后再拿别的。同样的道理,内部迭代时,项目可以透明地并行处理,或者用更优化的顺序进行处理。要是用 Java 过去的那种外部迭代方法,这些优化都是很困难的。这似乎有点儿鸡蛋里挑骨头,但这差不多就是 Java 8 引入流的理由了,Stream 库的内部迭代可以自动选择一种适合你硬件的数据表示和并行实现。与此相反,一旦通过写 for-each 而选择了外部迭代,那你基本上就要自己管理所有的并行问题了(自己管理实际上意味着“某个良辰吉日我们会把它并行化”或“开始了关于任务和 synchronized 的漫长而艰苦的斗争”)。Java8 需要一个类似于 Collection 却没有迭代器的接口,于是就有了 Stream !下面的图说明了流(内部迭代)与集合(外部迭代)之间的差异。
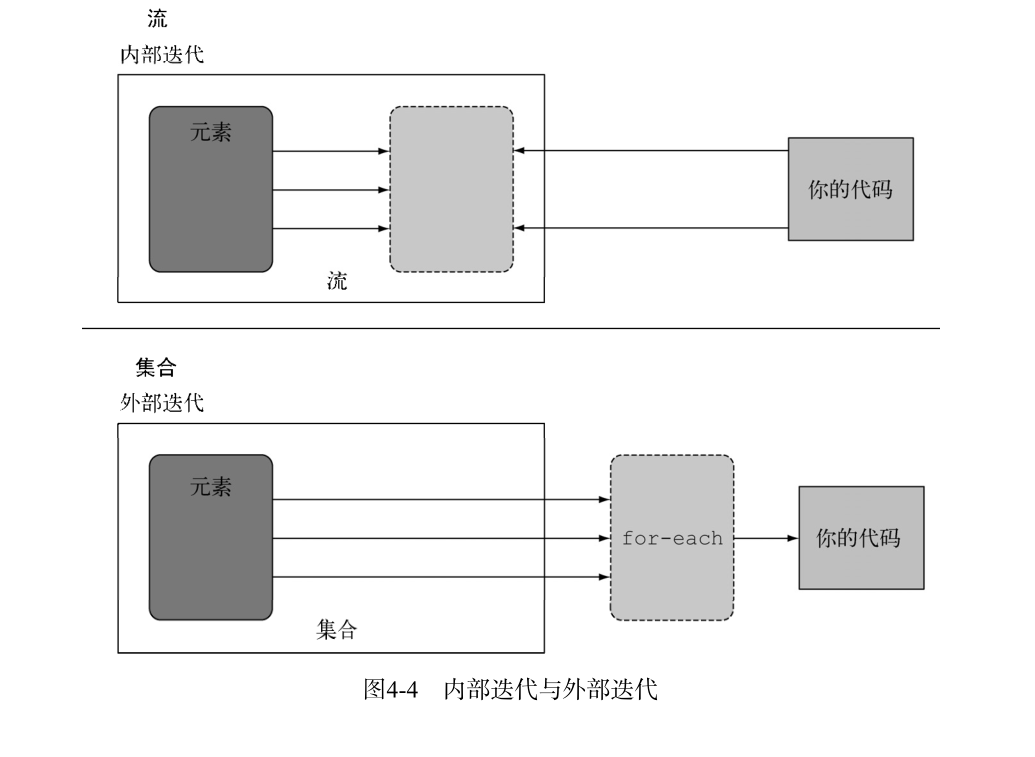
我们已经了解过了集合与流在概念上的差异,特别是利用内部迭代:替你把迭代做了。但是,只有你已经预先定义好了能够隐藏迭代的操作集合。例如 filter 或 map,这个才有用。大多数这类操作都接受 Lambda 表达式作为参数,因此我们可以用前面所了解的知识来参数化其行为。
流操作
java.util.stream.Stream 中的 Stream 接口定义了许多操作。它们可以分为两大类。我们再来看一下前面的例子:
List<String> names = menu.stream()
// 中间操作
.filter(d -> d.getCalories() > 300)
// 中间操作
.map(Dish::getName)
// 中间操作
.limit(3)
// 将 Stream 转为 List
.collect(toList());
filter、map 和 limit 可以连成一条线,collect 触发流水线执行并关闭它。可以连起来的称为中间操作,关闭流的操作可以称为终端操作。
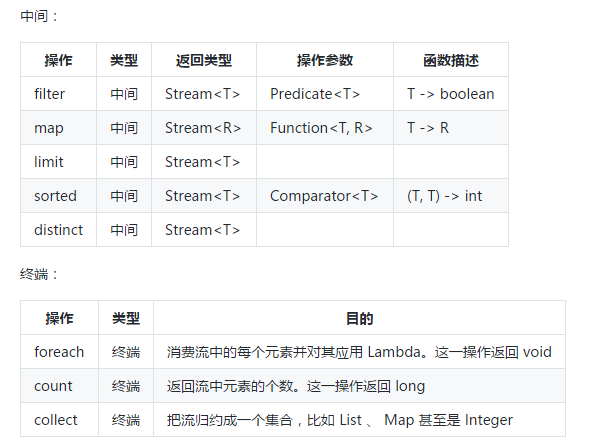
中间操作
诸如 filter 和 sorted 等中间操作会返回一个流。让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理它们懒得很。这就是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。
为了搞清楚流水线到底发生了什么,我们把代码改一改,让每个 Lambda 都打印出当前处理的菜肴(就像很多演示和调试技巧一样,这种编程风格要是搁在生产代码里那就吓死人了,但是学习的时候却可以直接看清楚求值的顺序):
List<String> names = menu.stream()
.filter(d -> {
System.out.println("filtering:" + d.getName());
return d.getCalories() > 300;
})
.map(dish -> {
System.out.println("mapping:" + dish.getName());
return dish.getName();
})
.limit(3)
.collect(toList());
System.out.println(names);
执行结果:
filtering:pork
mapping:pork
filtering:beef
mapping:beef
filtering:chicken
mapping:chicken
[pork, beef, chicken]
从上面的打印结果,我们可以发现有好几种优化利用了流的延迟性质。第一,尽管有很多热量都高于 300 卡路里,但是只会选择前三个!因为 limit 操作和一种称为短路的技巧,第二,尽管 filter 和 map 是两个独立的操作,但是它们合并到同一次便利中了(我们把这种技术叫做循环合并)。
终端操作
终端操作会从流的流水线生产结果。其结果是任何不是流的值,比如 List、Integer,甚至是 void。例如,在下面的流水线中,foreachh 返回的是一个 void 的终端操作,它对源中的每道菜应用一个 Lambda。把 System.out.println()传递给 foreach,并要求它打印出由 menu 生成的流中每一个 Dish:
menu.stream().forEach(System.out::println);
为了检验一下对终端操作已经中间操作的理解,下面我们一起来看看一个例子:
下面哪些是中间操作哪些是终端操作?
long count = menu.stream()
.filter(d -> d.getCalories() > 300)
.distinct()
.limit(3)
.count();
答案:流水线中最后一个操作是 count,它会返回一个 long,这是一个非 Stream 的值。因此,它是终端操作。
使用流
总而言之,流的使用一般包括三件事:
- 一个数据源(比如集合)来执行查询
- 一个中间操作链,形成一条流的流水线
- 一个终端操作,执行流水线,并能生成结果。
流的流水线背后的理念类似于构建器模式。 在构建器模式中有一个调用链用来设置一套配置(对流来说这就是一个中间操作链),接着是调用 built 方法(对流来说就是终端操作)。其实,我们目前所看的 Stream 的例子用到的方法并不是它的全部,还有一些其他的一些操作。
在本章中,我们所接触到的一些中间操作与终端操作: (V2EX 不支持表格语法?)
Stream 是一个非常好用的一个新特性,它能帮助我们简化很多冗长的代码,提高我们代码的可读性。
本章总结
- 流是“从支持数据处理操作的源生成的一系列元素”。
- 流利用内部迭代:迭代通过 filter、map、sorted 等操作被抽象掉了。
- 流操作有两类:中间操作和终端操作。
- filter 和 map 等中间操作会返回一个流,并可以链接在一起。可以用它们来设置一条流水线,但并不会生成任何结果。
- forEach 和 count 等终端操作会返回一个非流的值,并处理流水线以返回结果。 6.流中的元素是按需计算(懒加载)的。
代码示例
Github: chap4
Gitee: chap4
公众号
如果,你对 Java8 中的新特性很感兴趣,你可以关注我的公众号或者当前的技术社区的账号,利用空闲的时间看看我的笔记,非常感谢!

第 1 条附言 · 2018-08-25 12:08:45 +08:00
很抱歉,这个公众号的二维码让大家产生了一个误会。因为我写文章没多久我也在很多社区发过读书笔记的文章,因为写的不是很好,就想大家指出其中的不足,提升自己的写作水平和技术误区。技术菜,要学习啊所以就有学习笔记的文章,因为自学,错了可能也认为是对的。文章不能改了,底部的让人误会的二维码不能去除,非常抱歉。
 |
1
Cbdy 2018-08-25 10:37:43 +08:00 via Android
能不能先看一下 Java8 什么时候出来的再来发文章?下个月都 Java11 了,为什么还是 Java8 的“新”特性
|
 |
3
NGLSL OP @Cbdy 如果您觉得 Java8 太老了,您也可以去研究一下 Java11,写一下学习笔记,好让我们学习学习。不那么快被淘汰。
|

 |
6
awanabe 2018-08-25 11:49:00 +08:00 如果是 读书笔记
就留着自己看 没人愿意 你还厚脸皮贴出来 还是为了引流 不说破还蹬鼻子上脸 |

 |
10
wysnylc 2018-08-25 12:26:52 +08:00 写得还行啊,虽然相同内容一大把.
建议整理一下 JAVA9 中对 Stream 的更新 |
 |
11
blindpirate 2018-08-25 12:28:28 +08:00 大家一点都没误会,何必强行解释,不过这个文章放在现在真的毫无价值,Java8 已经 EndOfLife 了。
|
|
12
NGLSL OP @blindpirate 仔细想想,Java8 都已经被宣布要停止更新了,价值确实大不如以前。
|
 |
14
wocanmei 2018-08-25 13:18:33 +08:00 via iPhone 上面有的兄弟言语确实过激了点,大家都在争论 java8 新不新现在分享有没有价值的问题,我觉得肯定是有价值的,据我了解不少公司还在用 java6,java 虽然一直在演进但总体脉络还是稳定的嘛。在我看来大家讨厌的是 lz 的这种分享方式,写一篇就分享一次频率有点高乐哈,lz 控制一下频率,大家也别这么毒舌,毕竟也是知识分享嘛
|
 |
16
hdonghong 2018-08-25 19:43:00 +08:00
不过是想引流,哈哈哈
|
 |
17
yumenawei 2018-08-25 22:46:10 +08:00
楼主,别伤心。
感觉有些人戾气稍重。不喜欢关上就行了,哪那么多事啊。 |