
这是一个创建于 1966 天前的主题,其中的信息可能已经有所发展或是发生改变。
这是我们的一个大三课程的课程设计,我自认为做的还可以,就发上来,请各位看官点评一下,谢谢。
大概说说做了哪些功能:
- 做了道路的展示、排序和检索。以及比较了各种排序方法。
- 计算端用的 CPP,实现了 5 种排序方法,并改进了 1 种。
- 后端主要是作为一个中间件,从计算端获取结果,并给前端,主要用了 Flask。
- 前端用的是 ElementUI 和 Vue,主要用来做结果的展示
界面
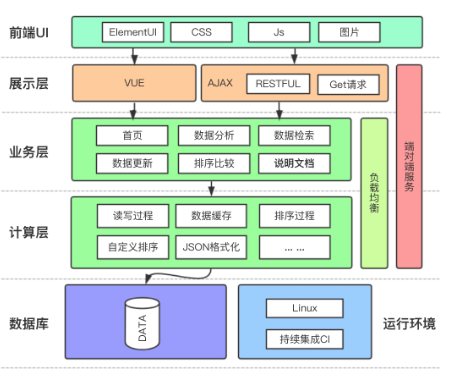
整个系统结构图大概类似这样
一些动图
检索界面

比较各种排序方法

改进排序方法
其实对于特定数据分布的排序,我们是可以通过看数据知道一些规律的:
-
比如 LINKID 字段,可以认为是均匀分布,因为是自增的关键字。对于这个字段的排序就比较适合桶排序(在 ID 不是特别多的情况下)。
-
再比如数量和番号字段,他们都是 20 以下的数,可以用较少的桶,但是每个桶内存放的 id 超过一个,就需要链表或者是预分配足够大的数组存,一个直接的改进思路就是通过两次扫描,第一次获取每个桶的元素数量,第二次就可以直接计算出这个元素的在排序好数组中的下标,然后直接做赋值操作即可。
-
对于字符串的字段,很多道路段共享着一个道路名称。我们可以结合倒排索引和桶排序的方法来做。
改进的结果:
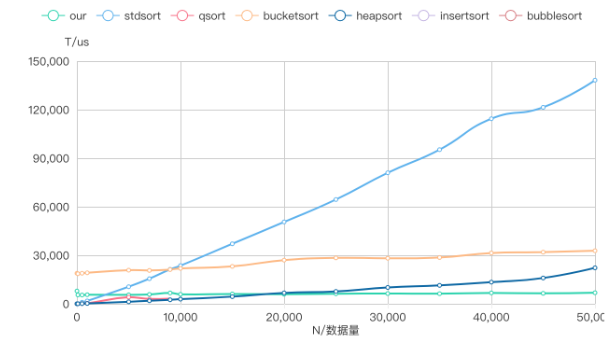
下图为在 LinkID 场景下的排序速度,可以看出改进方法在 N>25000 时,算法运行时间显著的小于最快的 BucketSort。在实际场景之下,N 往往大于 25000。
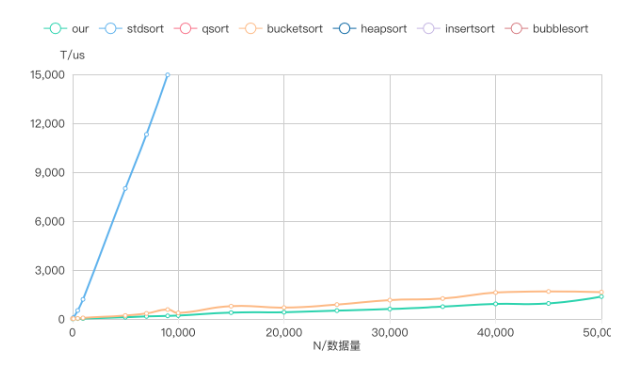
下图为在道路番号场景下的排序速度,效果还是不错的。
项目地址
https://github.com/chengsyuan/MapSystem
Docker
顺便包装到了 Docker 里面,就当练手了。用了 Daocloud 做持续集成。我觉得 Daocloud 现在没以前好用了。
 |
1
wudalang123 2019-11-27 08:33:04 +08:00
应用场景是什么?
|