› MySQL 5.5 Community Server
› MySQL 5.6 Community Server
› Percona Configuration Wizard
› XtraBackup 搭建主从复制
Great Sites on MySQL
› Percona
› MySQL Performance Blog
› Severalnines
推荐管理工具
› Sequel Pro
› phpMyAdmin
推荐书目
› MySQL Cookbook MySQL 相关项目
› MariaDB
› Drizzle
参考文档
› http://mysql-python.sourceforge.net/MySQLdb.html
MySQL 相关项目
› MariaDB
› Drizzle
参考文档
› http://mysql-python.sourceforge.net/MySQLdb.html

这是一个创建于 2002 天前的主题,其中的信息可能已经有所发展或是发生改变。
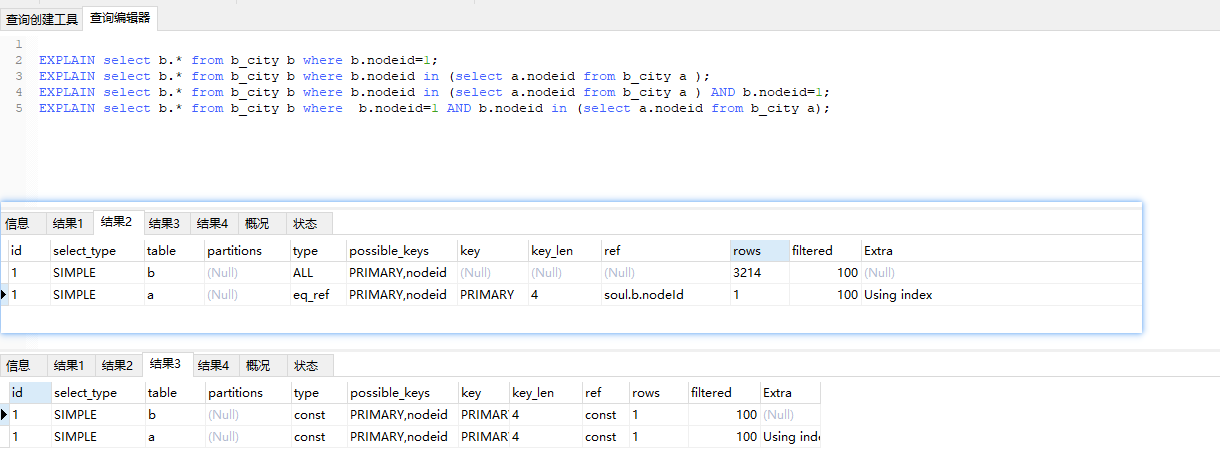
有两个问题请教下
1.第二个查询结果,顺序不应该是先查子查询吗,为啥 table b 先查( id 相同,执行顺序由上至下 )
2.第三个查询和第四个查询 explain 结果是一样的,是 mysql 做了优化了 吗
 |
1
JasonLaw 2020 年 8 月 4 日 via iPhone
nodeid 索引是唯一索引并且 nodeid 是 not null 。对吗?
|
|
2
JasonLaw 2020 年 8 月 4 日
如果是的话,那就可以解释了。
查询优化器可能将 select b.* from b_city b where b.nodeid in (select a.nodeid from b_city a)转化为 select b.* from b_city b where exists(select 1 from b_city a where a.nodeid = b.nodeid),然后又转化为 select b.* from b_city b where exists(select 1 from b_city a where a.id = b.id),它的执行可以做到跟展示的执行计划匹配,可以逻辑地理解为“检查 b_city 的每一行,对于每一行,查询是否存在 id 为这行 id 的 b_city”。 至于为什么不限执行 select a.nodeid from b_city a,不管是怎样,你都要检查 b_city b 的每一行,相比于检查 b_city b 的每一行的 nodeid 是否存在于 select a.nodeid from b_city a 所代表的集合中,为什么不直接检查 b_city a 中是否存在 nodeid 为 b_city b 行 nodeid 的行呢?如果 nodeid 索引是唯一索引并且 nodeid 是 not null 的话,它甚至可以做到“检查 b_city b 的每一行,检查 b_city a 中是否存在 id 为 b_city b 行 id 的行”。 |
|
3
JasonLaw 2020 年 8 月 4 日
但是这无法解释第三和第四条语句会使用 PRIMARY 那个 index,难道 PRIMARY 和 nodeid 两个 index 相关的列都是 nodeid ?
提供多一点信息吧,表结构以及数据。不然无法知道什么原因。 |
 |
4
sdfqwe OP @JasonLaw 你好,感谢你的回复,https://imgchr.com/i/arKzq0
|
|
6
sdfqwe OP CREATE TABLE `b_city` (
`nodeId` int(11) NOT NULL, `parentNodeId` int(11) DEFAULT NULL, `cityName` varchar(100) NOT NULL, `regionCode` varchar(100) NOT NULL, PRIMARY KEY (`nodeId`), KEY `nodeid` (`nodeId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='城市区划'; |
 |
8
xsm1890 2020 年 8 月 5 日
@JasonLaw @sdfqwe
select b.* from b_city b where b.nodeid in (select a.nodeid from b_city a)转化为 select b.* from b_city b where exists(select 1 from b_city a where a.nodeid = b.nodeid); 对于这一条是有问题的。在 5.5 版本之前是这么转化的。但是在 5.6 及后面的版本,MySQL 的优化器对子查询的优化策略是不一样的。 Convert the subquery to a join, or use table pullout and run the query as an inner join between subquery tables and outer tables. Table pullout pulls a table out from the subquery to the outer query |
|
9
xsm1890 2020 年 8 月 5 日
如果是唯一键的话是转化为 join 来进行优化的。所以第二条可以写成:
SELECT b.* FROM b_city b WHERE b.nodeid IN(SELECT a.node_id FROM b_city a)可以转化为 select b.* from b_city b join b_city a where a.nodeid=b.nodeid |
|
10
xsm1890 2020 年 8 月 5 日
可以使用 explain extended 加上 show warnings 来查看中间的转换结果
|
|
11
JasonLaw 2020 年 8 月 5 日
@sdfqwe 你的表为什么是这样子的?
1. nodeId 已经是 PRIMARY KEY 了,为什么还要定义一个多余的索引 nodeid 呢? 2. 为什么不直接叫 id 和 parentId 呢? nodeId 不会有什么业务含义吧? 3. 为什么城市表会有层级关系的呢? |
|
13
sdfqwe OP @JasonLaw 这个是我之前写的 demo,全国区域树,( http://139.129.221.236:81/),这个索引是我后来为了测试加上去的 https://s1.ax1x.com/2020/08/05/argYd0.png
|
 |
14
zhangysh1995 2020 年 8 月 5 日
@sdfqwe
直接 optimizer trace 导出来看看,https://dev.mysql.com/doc/internals/en/optimizer-tracing-typical-usage.html 第二条语句 b 类型是 ALL,应该就是全表扫了 第三句写了是 constant 类型,常数,说明 IN 查询被优化了,这也说明为什么用了索引,`1` 直接查询。 |
 |
15
wanglulei 2020 年 8 月 5 日
主键为啥还要创建一个索引呀
|