
这是一个创建于 1640 天前的主题,其中的信息可能已经有所发展或是发生改变。
本人是做科学计算的,简单来说就是解几百万几千万的大型稀疏矩阵。计算的性质决定了 Cache 命中率不会高。实际使用中,CPU 几乎很难达到瓶颈,运行速度基本与系统总内存带宽成正比。
最近在用超算的时候发现一个非常棘手的问题:内存带宽抢不过那些炼丹的。例如一台双路服务器有 24 个核,实际分配是 22 个核心给 CPU 任务,2 个核心给 GPU 任务。然而炼丹的抢内存带宽效率奇高。假如那台服务器碰巧有人在炼丹,我的计算速度几乎会减半,也就是说我用 22 个核心抢占内存带宽的速度和炼丹的 2 个核心差不多。但是超算的“价格”是按 CPU 核心 x 时间计算的,我消耗了 22 份的资源却只得到了 12 份的性能,实在是不太公平。
我这里没有贬低炼丹的意思,GPU 计算本身没有问题,我只是想提升自己程序抢占内存带宽的能力,得到我付出的“价格”应得的性能。
第 1 条附言 · 2021-03-07 13:38:33 +08:00
其实以前是没有这种破事的。就这两年炼丹火了以后,很多超算都单独划出来一两个核心给炼丹的用。可能系统管理员自以为提高了节点的利用率,但这实际上是个零和游戏。
 |
1
bbyan2006 2021-03-07 12:21:28 +08:00 via Android 关注。关注
|
 |
2
Kagari 2021-03-07 12:24:05 +08:00 via Android
是不是还有一种可能,你和炼丹的速度都减半了
|
3
F281M6Dh8DXpD1g2 2021-03-07 12:25:26 +08:00 via iPhone
把你的数据文件锁在内存里面
|
 |
4
xuegy OP @Kagari 但是我花了 22 份 SU 拿到了 12 份内存带宽。炼丹的花了 2 份 SU 也拿到了 12 份内存带宽,凭什么啊?
|
 |
5
lithiumii 2021-03-07 12:30:04 +08:00 via Android
跟卖服务器的聊聊,让他们改成按内存带宽收费?
|
 |
6
Yc1992 2021-03-07 12:43:32 +08:00
开 root 把炼丹程序 kill 掉
|
 |
7
0TSH60F7J2rVkg8t 2021-03-07 13:04:48 +08:00
弱弱问一句,啥是炼丹的程序啊?
|
 |
8
zckevin 2021-03-07 13:04:57 +08:00
|
 |
10
noqwerty 2021-03-07 13:15:17 +08:00
把你的数据文件都放到 /dev/shm 下面?
|
|
11
zckevin 2021-03-07 13:30:47 +08:00
@xuegy 没有,只是看到你的问题想到而已。似乎现在的 kernel 是无法对内存带宽做限制的,而且两个频繁 cache miss 访存的应用,除非把另一个干掉,不然注定是会达到各自占用一半带宽的均衡状态吧。我感觉稍微靠谱的方法应该是给 sysadmin 写邮件去商量。
|
 |
12
f165af34d4830eeb 2021-03-07 13:32:31 +08:00
实在不行找老板申请买服务器吧,有经费就拿来花嘛,何必跟自己过不去呢。
|
|
13
xuegy OP @f165af34d4830eeb 超算是我们写 proposal 申请来的,都没花钱,为啥要自己买...
|
14
jr55475f112iz2tu 2021-03-07 13:41:08 +08:00 via Android @ahhui 机器学习
|
 |
15
hitmanx 2021-03-07 13:56:46 +08:00
这事应该向服务器提供商去询问,而不是你自己去想办法。
你是他的客户,甚至是大客户,你花了 22 份的钱,炼丹的只花了 2 份的钱,他不会为了这些“添头”失去大客户的 |
|
16
f165af34d4830eeb 2021-03-07 13:57:41 +08:00 via iPhone
@xuegy 你要用超算那就得和别人挤嘛,毕竟超算是共享的,组里不差钱搞个好点的机器又不是不行。
|
|
17
f165af34d4830eeb 2021-03-07 14:02:56 +08:00 via iPhone
或者用纯 cpu 节点的超算?这样就不担心有炼丹佬抢你们 cpu 了
|
|
18
f165af34d4830eeb 2021-03-07 14:03:51 +08:00 via iPhone
@hitmanx 我猜是学校或者研究所的机器,学生没话语权,管理员才不管这些事
|
|
19
xuegy OP @f165af34d4830eeb 可以认为是学校的机器吧,不过管理员想管也管不了啊。我还从来没听说过有什么东西能限制进程访问内存占用带宽的,只能从自己这想办法了。
|
|
20
xuegy OP @f165af34d4830eeb 纯 CPU 的节点,随着这一波 Xeon 换 EPYC 的大潮,基本快要绝迹了。
|
|
21
f165af34d4830eeb 2021-03-07 14:14:30 +08:00 via iPhone
@xuegy 我觉得你还是和老板商量下吧,没必要帮老板省经费的,除非你们组有别的地方要花钱。隔壁组单机八路 3080 快把我馋哭了,有钱真好...
|
|
22
xuegy OP @f165af34d4830eeb 这么跟你说吧,我们组写 proposal 没花一分钱从 NSF 白嫖了五百万 SU ( 500 万核心*小时),这些东西要是自己买,别说机器价格,电费就得多少....
|
|
23
f165af34d4830eeb 2021-03-07 14:26:21 +08:00 via iPhone
@xuegy 真有这个运算量不应该沦落到和炼丹佬抢机时啊...但是你们这个和炼丹的抢内存确实没啥好办法,你又不能把对方踢掉,对方也不愿意让出机时,这个问题估计还得靠老板出面解决。
|
|
24
xuegy OP @xuegy 你还是低估了炼丹佬,虽然炼一次只占一个核但架不住量大啊。我随便敲一下 squeue,好几十屏都是只开单核的 GPU 任务。
|
 |
25
Lemeng 2021-03-07 14:36:25 +08:00
是后台程序的意思吧
|
 |
26
Sasasu 2021-03-07 14:40:26 +08:00 用 GPU 走 DMA 和中断抢内存带宽,优先级就是比普通的程序高.....
|
27
jr55475f112iz2tu 2021-03-07 14:45:06 +08:00 via Android
@xuegy Xeon 换 EPYC 大潮可以展开讲讲吗? Intel 在服务器端也要守不住了?大快人心
|
|
28
xuegy OP @czfy 我不知道国内是什么情况,反正美帝这两年只要 Intel 超算退役了,基本新换上来的都是 EPYC 。因为 AMD 核心数量多好几倍,跑那些内存占用小的,L3 就能装满的 benchmark,速度确实起飞。跑分好看自然可以忽悠学校和研究所换平台。但实际上对于我们这种 cache 几乎必定 miss 的程序来说,Intel 6 通道 VS AMD 8 通道,性能提升真的不大。
|
|
29
0TSH60F7J2rVkg8t 2021-03-07 15:07:35 +08:00
@czfy 多谢指教
|
 |
30
zwy100e72 2021-03-07 17:21:56 +08:00
有没有可能优化内存访问效率,提升一下 cache 命中率呢?
毕竟顺序读取的访问效率就是比随机访问效率高 (cpu prefetch) |
 |
31
Knights 2021-03-07 17:23:33 +08:00
技术上不好解决啊,让管理员按时间段划分使用呗
|
 |
33
abbottcn 2021-03-07 17:49:03 +08:00 via iPhone
诸如 slurm 之类的调度器,似乎只能限制内存容量,而不能限定带宽。slurm 通过 cgroup 做限定。
另外说个笑话。一个生物课题组计算出了问题,找我解决。我一看,双路机器,两张 GPU,却只有两个 8GB 内存条,计算基本都是内存不足而挂掉的。他们以为,GPU 计算,和 CPU 内存没啥关系。要是再无知点,估计都能用一个内存条。 |
|
35
abbottcn 2021-03-07 18:02:56 +08:00 via iPhone
@xuegy 你还没看过,四路 8 系列处理器服务器,用四个 64GB 内存条的。
常见的是,双路机器,8 系列处理器,用四个或者八个内存条的。 来问我,我都说,8 系列处理器,双路,不用 12 个内存条的,基本是傻子。同理,四路机器,v3v4 处理器,用 16 个内存条,8 系列,用 24 个内存条呀。高校一窝蜂做计算的很多,买的机器配置搞笑的特别多。 |
|
36
xuegy OP @abbottcn 我们组中东土豪自费攒的电脑,内存条倒是插满了,愣是不知道去 BIOS 开一下 XMP,DDR4 3600 跑在 2133,损失了快一半带宽...
|
37
jr55475f112iz2tu 2021-03-07 18:30:03 +08:00
@xuegy 性能提升不大,至少有提升,但价格会有变吧?
|
 |
38
skies457 2021-03-07 18:34:36 +08:00
或许可以也用 GPU 解矩阵....
|
 |
39
nlzy 2021-03-07 19:33:04 +08:00 via Android 打不过就加入,你也用 GPU 解矩阵
|
 |
40
ziseyinzi 2021-03-07 19:50:36 +08:00
还没听说过主机管理员能管理内存带宽的,甚至带宽占用都不知道怎么看
|

|
42
f165af34d4830eeb 2021-03-07 20:30:49 +08:00
@xuegy 所以国内有一点好,这种技术上不太好解决的问题,可以通过加钱 /行政手段去解决。。
|
 |
43
yazoox 2021-03-07 22:22:20 +08:00
为啥超算才 24 核心?不是很懂,这玩意儿,不是几千几万个么?
|
 |
44
dangyuluo 2021-03-07 23:24:11 +08:00
好玩,不过应该不好办,毕竟是按核心卖而不是按内存带宽卖的。不过这不是个零和游戏,二十个负核游戏。虽然 wakuang 得到了更多内存带宽,但是并没有得到更多的算力,而你损失了算力。
|
 |
45
updateing 2021-03-07 23:52:18 +08:00 via Android Intel RDT 提供了使用软件对 cache 和内存带宽做分配的功能,但我不了解 GPU 用 DMA 抢带宽能否一起限制。或许可以看看: https://www.intel.cn/content/www/cn/zh/architecture-and-technology/resource-director-technology.html
|
|
46
xuegy OP @czfy 价格我就不知道了,人家买都是有技术支持的整机,硬件成本只是其中一部分。我只能说如果想自己攒一台工作站的话价格其实差不多,反正大头在内存上。
|
|
48
xuegy OP @updateing 是通过限制 L3 的方式来控制内存带宽的么...看简介的确是我想要的,不过显卡 DMA 很有可能管不到。
|
|
49
xuegy OP @dangyuluo 我个人认为最理想方式是专门弄 GPU 节点,就像矿机那样的,炼丹师们自己去跟自己抢。这样他们自然会想办法减少 GPU 和内存的数据交换。
|
50
jr55475f112iz2tu 2021-03-08 01:54:33 +08:00
@xuegy 嗯。目前其实 AMD 和 Intel 的差距主要在软件生态上,给一两年追上来了之后,竞争力会更强
|
|
51
xuegy OP @czfy x86 在超算没有什么区别,AMD 又不是不支持 AVX2 。硬要说区别的话,英特尔有 icc,AMD 是 Clang 魔改的 AOOC 。不过 icc 那个兼容性实在是太烂了。
|

 |
53
FindHao 2021-03-08 02:39:59 +08:00 via Android
@xuegy gpu 有双精度,超算一般都是 tesla 系列的,硬件 fp64 是完整的。即便不是 tesla,geforce 的也有双精度,只不过性能差一点。
|
|
54
xuegy OP @FindHao 我知道有用 GPU 算的,CPU 把矩阵组装好以后送进 GPU 迭代,依旧无法克服内存瓶颈的问题。
|
 |
55
Ehco1996 2021-03-08 07:34:20 +08:00
让 admin 用 cgrou 做隔离?
|
 |
56
dbpe 2021-03-08 08:45:04 +08:00
就不能把炼丹放在一起,一起练蛊么
|
 |
57
heart4lor 2021-03-08 10:30:44 +08:00
双路服务器 NUMA 架构访问内存的速度是不一样的,可以参考 http://cenalulu.github.io/linux/numa/ 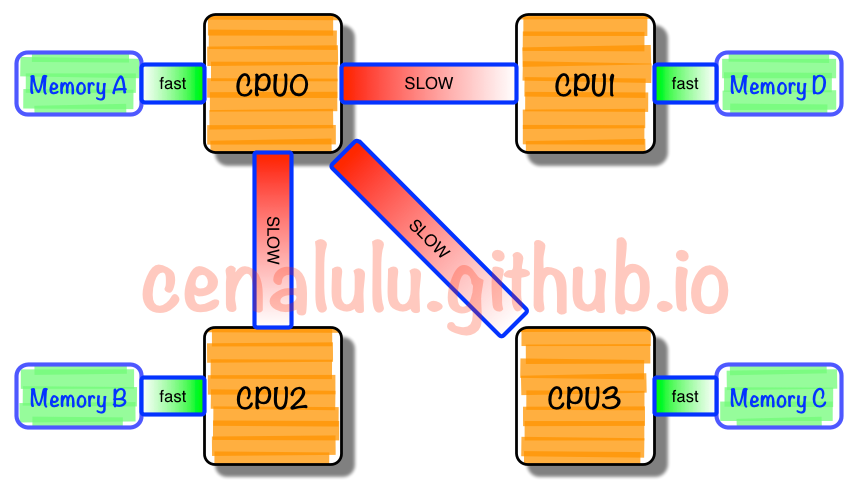
|
 |
58
karatsuba 2021-03-08 10:49:11 +08:00
想问一下炼丹是什么意思
|

 |
60
wsy2220 2021-03-09 00:04:37 +08:00
花钱即可
|
 |
61
512557852 2021-04-06 12:00:01 +08:00
用 24core 独占整个 CPU
|