› MySQL 5.5 Community Server
› MySQL 5.6 Community Server
› Percona Configuration Wizard
› XtraBackup 搭建主从复制
Great Sites on MySQL
› Percona
› MySQL Performance Blog
› Severalnines
推荐管理工具
› Sequel Pro
› phpMyAdmin
推荐书目
› MySQL Cookbook MySQL 相关项目
› MariaDB
› Drizzle
参考文档
› http://mysql-python.sourceforge.net/MySQLdb.html
MySQL 相关项目
› MariaDB
› Drizzle
参考文档
› http://mysql-python.sourceforge.net/MySQLdb.html

这是一个创建于 1563 天前的主题,其中的信息可能已经有所发展或是发生改变。
sql 执行语句 SELECT timestrap, bps FROM cdn_bandwidth WHERE (company_id = 1 AND domain_id IN (242,292,194,264,217,195,203,200,198,221,227,335,167,243,261,218,196,176,174,162,161,160,170,173,325,169,324,171,236,241,220,256,276,186,263,254,286,287,285,288,283,278,291,215,334,260,321,316,318,319,323,322,163,159,213,207,238,274,164,333,280,249,247,246,252,273,255,181,180,248,226,178,179,293,265,301,237,175,240,262,166,305,326,304,165,177,259,225,183,214,193,197,206,290,257,258,219,189,172,209,267,210,271,272,229,302,300,303,275,320,239,284,205,208,182,191,190,277,250,298,295,297,269,216,187,232,230,231,251,185,294,244,245,281,168,268,188,184,223,202,222,192,224,332,282,199,270,266,289,296,234,253,201,233,235,279,211,315,228,204,212) AND time BETWEEN '2021-12-01 00:00:00' AND '2021-12-26 23:59:59')
查询出 1038259 条数据,共花费时间 125 秒。太长时间了。有没有办法能优化下。
第 1 条附言 · 2021 年 12 月 27 日
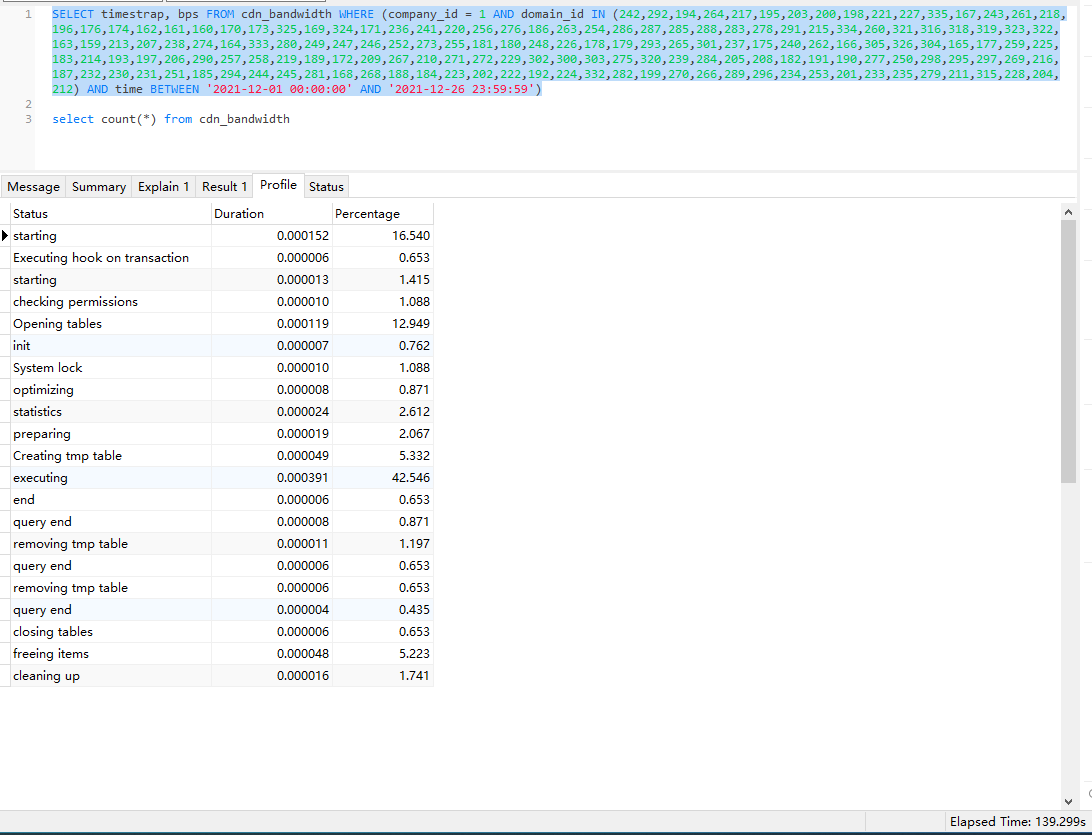
第 2 条附言 · 2021 年 12 月 27 日
数据库表主要是用于存放域名的带宽数据,每个域名每 5 分钟一条数据,域名比较多,最多查询一个月数据,所以数量上就会比较多。
第 3 条附言 · 2021 年 12 月 27 日
因为查询最后需要合并数据结果,就查询的所有域名的相同时间的数据相加,这部因为觉得查询就很慢了,所以返回结果用 python 计算了
第 4 条附言 · 2021 年 12 月 27 日
索引
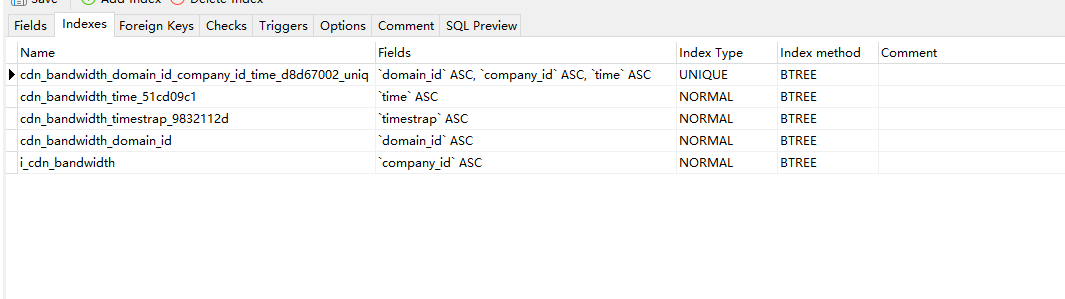
第 5 条附言 · 2021 年 12 月 27 日

第 6 条附言 · 2021 年 12 月 30 日
因为数据库是在不熟悉,公司只有一位稍微懂点的同事,给我的意见都是分表,因为 IN 的条件太多了,无论如何都快不了的,所以还是用了最笨的方法,按天查询,每次返回的结果在用 pandas 处理,一个月的数据其实就是请求数据库 30 次,速度已经从 120s 降到了 20s ,虽然还是觉得太慢了,接下来试试能不能从多线程的思路解决,提高请求 mysql 的效率看看能不能再优化下,谢谢各位大佬。
84 条回复 • 2022-01-02 16:11:26 +08:00
 |
1
harde 2021 年 12 月 27 日
没索引吧?
|
 |
2
gadfly3173 2021 年 12 月 27 日
https://github.com/XiaoMi/soar 可以试试这个 不过看你的数据量也优化不了什么了。。。
|
 |
3
jenlors 2021 年 12 月 27 日
执行计划贴一下
|
|
4
harde 2021 年 12 月 27 日
单表数据量多大? 提问题的同时请让大家尽可能多的了解你的情况
|
 |
5
cheng6563 2021 年 12 月 27 日
给 time 上索引
|
 |
6
icaca 2021 年 12 月 27 日
125s 肯定没走索引,表也不大
把所有列都加上索引。然后尽量把 in 换成 join 。 优化到 100 毫秒应该没问题的。 |
 |
7
des 2021 年 12 月 27 日 via iPhone “ 查询出 1038259 条数据” 好好想想,你页面需要展示这么多数据?
|
 |
8
cloverzrg2 2021 年 12 月 27 日
数据返回时间多少秒?
|
 |
9
182247236 OP @des 查询出来的数据还需要写个 sum ,查询就这么慢了我就用 python 处理了,所以实际到最后的数据没有这么多的,就是查询这部太久了
|
|
10
182247236 OP @cloverzrg2 这个在哪里看?我是看 navcat 右下角 elapsed time 的
|
 |
13
vanton 2021 年 12 月 27 日
explain 贴一下吧,你这样啥都看不出
|
|
14
cloverzrg2 2021 年 12 月 27 日
@182247236 #10 可能有个 transfer data 之类的时间,你可以简单把 sql 改成 select (*) from 执行看一下时间
|
 |
15
kujio 2021 年 12 月 27 日
1.将数据按时间拆分成多个表:减少查询范围,
2.查询结果看看在业务上能不能拆分:减少查询结果, |
 |
18
gesse 2021 年 12 月 27 日
按照你的表查询的内容、数据量来说, 其实应该可以从几个方面来优化:
1. 按照历史日期分表 2. 按数据活跃度分表 3. 历史不会修改数据放入只读数据库,加快数据检索速度 https://help.aliyun.com/document_detail/26136.html …… 等等 |
|
21
harde 2021 年 12 月 27 日
索引是什么样子的,顺便也贴一下。即使单表上千万条,你这个业务查询也不需要这么久
|
|
22
icaca 2021 年 12 月 27 日 一千万查一百万数据出来,走不走索引,差别都不大的
|
|
23
icaca 2021 年 12 月 27 日
建议你在业务层优化下,单独起个服务做统计吧。
|
 |
24
rsyjjsn 2021 年 12 月 27 日
前端门外汉,不过我司貌似每天都在扯千万级别的数据量,解决都是分表分库
|
 |
25
liyunyang 2021 年 12 月 27 日
期待一下后续
|
 |
26
wolfie 2021 年 12 月 27 日
贴 explain 啊。
force 联合索引看看。 |
 |
27
lolizeppelin 2021 年 12 月 27 日
换 pg 上时序 哈哈哈哈
|
 |
28
duhui 2021 年 12 月 27 日
>每个域名每 5 分钟一条数据
能不能每天统计一次, 然后一个月的话就算 30 天 |
 |
29
justfindu 2021 年 12 月 27 日 不如另外跑一个数据归档吧. 比如按天归档, 这样数据量就可以降低 288 倍. 你这个查出来的数据量很大, 有没有索引真的差别不大了.
|
 |
30
Soar360 2021 年 12 月 27 日
查询出 1038259 条数据
这么多数据,仅仅是查出来,就算走索引网络传输也要好久了吧。我觉得你需要中间表了。 |
 |
31
zibber 2021 年 12 月 27 日
in 查询条件多了会不走索引
|
 |
32
akira 2021 年 12 月 27 日
另外建一个每日数据汇总表,每天统计一次。
每月的这个汇总表就可以直接基于每日的汇总就好了 |
 |
33
justicelove 2021 年 12 月 27 日
1. 表按时间分区
2. 试试对 domain_id 创建一个直方图 |
 |
34
roiding 2021 年 12 月 27 日
in 这么多字段 你确定走了索引?
|
 |
37
28Sv0ngQfIE7Yloe 2021 年 12 月 27 日
看起来你需要一个 OLAP 数据库,或者离线处理?
|
|
38
182247236 OP 我用 zabbix 或者别的一些数据监控,他们的都是 1 分钟存一条数据,数据量比我的大多了,怎么别人的查询就这么快...
|
|
39
wolfie 2021 年 12 月 27 日
@182247236 #36
这索引就过滤一个 company_id from table force index() -- 这里添加 force ,括号值写 unique 索引全名 where ... ... |
|
40
jenlors 2021 年 12 月 27 日
为什么要使用 unque 类型的索引,试试强制使用那个联合索引,按理说可以使用到这个索引
|
 |
41
chengyunbo 2021 年 12 月 27 日
表结构贴一下呢,看这个 explain ,time 没走到索引,另外千万级别的数据量,是要考虑中间表了,或者 es 这种,单从时间上看是 time 字段没走索引导致耗时很高
|
 |
42
clf 2021 年 12 月 27 日
如果只写不删不更新,只用于统计。我觉得你可以考虑一下 clickhouse 用于存储此类数据。
另外,数据计算,python 不一定比数据库快……建议直接在数据库 SQL 里完成统计,因为数据库和 python 间还有数据传输开销。 |
|
44
182247236 OP 实在是头大,数据库知识不太懂,也是边做边学。有懂的请指教下!
|
 |
45
zengguibo 2021 年 12 月 27 日
这种最好优化了,就是按时间分表,一个月一张表,里面再加索引,到时候删除也方便
|
|
46
182247236 OP 另外如果我查询 1 天的数据是飞快的,我还以为 30 天的数据也就是递增查询就完了
|
 |
47
RangerWolf 2021 年 12 月 27 日
查询 1M 条数据,感觉无论如何也快不到哪里~ 如果可以使用 Clickhouse 之类的计算,可以直接计算汇总数据。速度要快的多~
MySQL 本身确实不是很适合做这个事情。 不知道这个表还有没有其他的字段,实在不行可以尝试给第一个索引增加新的字段,把 timestrap 跟 bps 都加到联合索引之中,这样就不需要回表查询,理论上会快很多。 |
 |
48
lscho 2021 年 12 月 27 日
数据库在哪?你在哪查的?
|
 |
50
xhcarlin 2021 年 12 月 27 日
如果有办法强制指定用那个联合索引,应该会快一些才对
|
 |
51
xinJang 2021 年 12 月 27 日
我第一反应是子查询,果然数据库不行,泪奔
|
|
52
xhcarlin 2021 年 12 月 27 日
我现在的业务也有很多这类日志,不过用的是 mongodb ,单表也有 1500w+了。一般我们是做一个每日的中间表,然后数量就一下子下来了,python 这边压力也小一点
|
|
53
182247236 OP 我现在检查到第一个问题,首先我查一天的所有数据需要的时间是 1s 左右,但是没走索引,所以我的索引是不是做的有问题?
|
|
54
jenlors 2021 年 12 月 27 日
看看这个,https://dev.mysql.com/doc/refman/8.0/en/index-hints.html ,使用 force index
|
|
55
jenlors 2021 年 12 月 27 日
如果可以加下 limit 之类的,返回数据太多了
|
 |
56
freelancher 2021 年 12 月 27 日
请个 DBA 。例如我。收费帮优化。
|
 |
57
neptuno 2021 年 12 月 27 日
每天、或者每半天统计一次。然后再去计算一个月的
|
 |
58
w0017 2021 年 12 月 27 日
时间字段加索引,把 BETWEEN AND 换成大于小于
|
 |
59
zhoudaiyu PRO 开个 SSH ,让我上去看看🐶
|
 |
60
rrfeng 2021 年 12 月 27 日
根本解决方案:上时序数据库。
SQL 优化:加索引,预聚合,联合索引。 |
 |
61
SmiteChow 2021 年 12 月 27 日
explain
|
 |
62
PeterZeng 2021 年 12 月 27 日
你查询结果字段在没在联合索引里面,不在还要回表查那就很慢了
|
 |
63
fiypig 2021 年 12 月 27 日 via iPhone
定时器报表统计啊
|
 |
64
chuann 2021 年 12 月 27 日
SELECT [...] FROM cdn_bandwidth WHERE [...] force index [explain 结果中那个 possible_keys]
|
|
65
icaca 2021 年 12 月 28 日
我之前看错了 以为表有 100w 数据
实际情况是查询结果有 100w 那基本上快不起来的(查询和传输)另外这么多数据应用端也容易挂掉 最好还是优化业务 降低返回的结果集的数量 建议是 尽量在数据库完成统计(我看业务并不复杂,应该 group by + sum ,就能搞定了吧?) 实在不行就做一个统计的服务,最终效果肯定好很多,但是维护起来会麻烦一些(主要是害怕统计业务挂掉) |
 |
66
void1900 2021 年 12 月 28 日
每个域名单独查
|
 |
67
opengps 2021 年 12 月 28 日
粗略的办法:where 用到哪些列,就给那些列来个组合索引
|
 |
68
yogapants 2021 年 12 月 28 日
估计是数据太大,服务器硬件怎么样,数据库服务器是否是专机专用的有跑其他服务么,explain 一下看看啥原因,查询字段加索引尽量走覆盖索引,如果真的是数据量太大不行就上 TIDB 试一下。实在不行专门起一个定时服务项目跑统计服务,放到 redis 里面。
|
 |
69
vone 2021 年 12 月 28 日
> 因为查询最后需要合并数据结果,就查询的所有域名的相同时间的数据相加,这部因为觉得查询就很慢了,所以返回结果用 python 计算了
这句话应该是错的,sum 并不耗时,把 100w 行数据取回本地才是非常耗时的操作。 |
 |
70
nekoneko 2021 年 12 月 28 日
1. 明显的没走索引
2. 先 count(*) 或者 sum 看看去掉数据传输用时多久,应该也不会快 3. 联合索引去掉 domain_id,先 time 后 company_id 试试,考虑到回表把 timestrap 和 bps 也加到索引里面 |
 |
71
GeminiPro 2021 年 12 月 28 日
返回 100w 数据感觉也正常吧,数据量太大了
|
 |
72
vinceall 2021 年 12 月 28 日
company_id domain_id time 加索引,explain 看看,会不会锁表
|
 |
75
Protocol 2021 年 12 月 28 日
解决了吗,楼主更新下问题进度
|
 |
76
MartinWu 2021 年 12 月 28 日
建议直接上 clickhouse ,加个 mysql engine 表,然后创建一个物化视图。
|
 |
77
liuhouer 2021 年 12 月 28 日
clickhouse + cloudcanal ,表用 replacemergetree ,设置自动 optimize ,0.1 秒返回结果,压缩率是 mysql 的 7+倍
|
 |
78
changs1986 2021 年 12 月 29 日
看 explain, 走的 domain_id 索引, domain_id 区分度可能不太好. 建议调整下 time 的索引, 调整成 index(time, domain_id, company_id), 然后 where 改成 where time BETWEEN '2021-12-01 00:00:00' AND '2021-12-26 23:59:59' and domain_id in (xx,xx) and company_id=1
|
|
79
182247236 OP 因为数据库是在不熟悉,公司只有一位稍微懂点的同事,给我的意见都是分表,因为 IN 的条件太多了,无论如何都快不了的,所以还是用了最笨的方法,按天查询,每次返回的结果在用 pandas 处理,一个月的数据其实就是请求数据库 30 次,速度已经从 120s 降到了 20s ,虽然还是觉得太慢了,接下来试试能不能从多线程的思路解决,提高请求 mysql 的效率看看能不能再优化下,谢谢各位大佬。
|
 |
80
ouxch 2021 年 12 月 31 日
初看这个问题,从已提供的信息来看,只修改 sql 应该就能得到很大的优化,对索引调整可进一步优化。
如不介意提供下:表结构语句、行数、期望输出、数据库实例(所在机器)的 CPU 核心数和内存大小 |
 |
81
orzwalker111 2021 年 12 月 31 日
1.show index from t; 看下每个索引对应的统计行数 Cardinality
2.建立联合索引(index_company_id_time_domin_id),company 和 time 哪个放左边,取决于谁的 Cardinality 大(统计数不太准确,domin_id 如果只是 in 操作使用的话,也可以不用放到联合索引,因为 5.6 有个”索引下推“技术能解决筛选问题) 3.select timestrap, bps 这两个字段都不存在索引,所以每行记录都会回表——建议直接 select id ,然后再通过 ids 去查 timestrap, bps ,减少回表次数 ----一个月 100 万数据,总表应该很大 rows 了,重新建立索引是个比较麻烦的事 ----能联合索引就联合索引,别搞这么多单字段普通索引——都是坑 |
|
82
orzwalker111 2021 年 12 月 31 日
其实还有个问题,一个月 100w 数据,单靠这种方式去统计,数据量大了一定会有问题。考虑下增量方式处理,先确定好最终需要的统计结果模型,然后建立以天(或其他粒度)维度的新表记录;新表订阅原表的 DML 操作(业务代码),异步更新新表,最后统计、展示时只需要查新表就 OK 了
|
 |
83
zzmark06 2022 年 1 月 2 日 via Android
统计,建议扔了 mysql ,你这场景不适合
考虑 hdfs ,clickhouse ,再来 10 倍量也能秒查 |
|
84
zzmark06 2022 年 1 月 2 日 via Android
bps ,timestamp ,时序性数据上时序专用库也可以,总之比这个要好,现在这用法再怎么优化也快不起来的
|