
Push 还是 Pull,揭秘 MatrixOne 数据库的 Pipeline 构建方式
dengn · 2022-06-01 16:45:58 +08:00 · 1324 次点击这是一个创建于 1212 天前的主题,其中的信息可能已经有所发展或是发生改变。
Push 还是 Pull ,揭秘 MatrixOne 数据库的 Pipeline 构建方式
作者简介:
颜文泽 矩阵起源高级研发工程师
MatrixOne 数据库是什么?
MatrixOne 是一个新一代超融合异构数据库,致力于打造单一架构处理 TP 、AP 、流计算等多种负载的极简大数据引擎。MatrixOne 由 Go 语言所开发,并已于 2021 年 10 月开源,目前已经 release 到 0.4 版本。本文将通过讨论数据库的 SQL 计算引擎的 Push 和 Pull 模型来揭秘 MatrixOne 的数据库 Pipeline 的构建方式。
Github 地址: https://github.com/matrixorigin/matrixone 有兴趣的读者欢迎 star 和 fork 。
数据库流水线 Pipeline 的构建方式
数据库的 SQL 计算引擎负责处理和执行 SQL 请求。通常来说,查询优化器会输出物理执行计划,它通常由一系列 Operator 组成,为了确保执行效率的高效,需要将 Operator 组成流水线执行。
有两种流水线的构建方式:第一种是需求驱动的流水线,其中一个 Operator 不断从下级 Operator 重复拉取下一个数据 Tuple ;第二种是数据驱动的流水线,由 Operator 将每个数据 Tuple 推送给下一个 Operator 。那么,这两种流水线构建,哪种更好呢? 这可能并不是一个容易回答的问题,在 Snowflake 的论文中提到:基于 Push 的执行提高了缓存效率,因为它将控制流逻辑从数据循环中移除。它还使 Snowflake 能够有效地处理流水线的 DAG 计划,为中间结果的共享和管道化创造了额外的机会。
下边这幅来自参考文献[1]的图最直接地说明 Push 和 Pull 的区别:
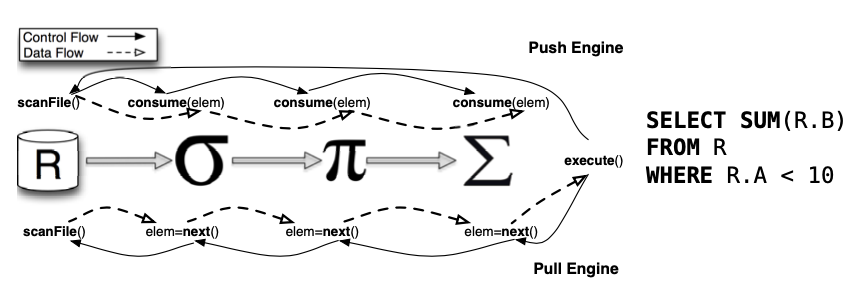
Pull Pipeline
简单地说,Pull 流水线基于迭代器模型,经典的火山模型正是基于 Pull 来构建。火山模型是数据库成熟的 SQL 执行方案,该设计模式将关系型代数中的每一种操作抽象成一个 Operator ,整个 SQL 语句在这种情况下形成一个 Operator 树(执行计划树);通过自顶向下的调用 next 接口,火山模型能够以数据库行为单位处理数据,就是图中所示的 next()方法。这种请求是递归调用的,直到查询计划树的叶子结点可以访问数据本身。因此,对于 Pull 模型来说,这是非常容易理解和实现的:每个 Operator 都需要实现 next()方法,只要将查询计划树构建好,就递归调用即可。火山模型有如下特点:
- 以数据行为单位处理数据,每一行数据的处理都会调用 next 接口。
- next 接口的调用,需要通过虚函数机制,相比于直接调用函数,虚函数需要的 CPU 指令更多,因此更昂贵。
- 以行为单位的数据处理,会导致 CPU 缓存使用效率低下和一些不必要的复杂性:数据库必须记住处理到哪一行,以便处理跳到下一行;其次处理完一行后需要将下一行加载到 CPU 缓存中,而实际上 CPU 缓存所能存储的数据行数远不止一行。
- 火山模型最大的好处是接口看起来干净而且易懂。由于数据流和控制流在一起,每个 Operator 有良好的抽象,比如 Filter 只需要关心如何根据谓词过滤数据,Aggregates 只需要关心如何聚合数据。
为了降低开销,Pull 模型可以引入向量化加速,就是实现 GetChunk()方法每次获取一批数据取代 next()获取一行数据,以 Projection 算子为例说明:
void Projection::GetChunk(DataChunk &result) {
// get the next chunk from the child
child->GetChunk(child_chunk);
if (child_chunk.size() == 0) {
return;
}
// execute expressions
executor.Execute(child_chunk, result);
}
这里边,存在一些跟控制流有关的代码,它跟 Operator 的处理逻辑耦合在一起,且每个 Operator 实现都要包含这些代码,例如这里需要判断 child_chunk 为空的情况,因为 child 在 GetChunk 时进行了过滤处理。因此,Pull 模型的接口内部实现比较冗余和易错。
Push Pipeline
与 Pull 流水线的迭代器模型不同,在 Push 模型中,数据流和控制流是相反的,具体来说,不是目的 Operator 向源 Operator 请求数据,而是从源 Operator 向目的 Operator 推送数据,这是通过源 Operator 将数据作为参数传递给目的 Operator 的消费方法(Consume)实现的,因此,Push 流水线模型等价于访问者(Visitor)模型,每个 Operator 不再提供 next ,而换之以 Produce/Consume 。Push 模型是 Hyper 提出的[3],称之为 Pipeline Operator ,它提出的初衷,是认为迭代器模型以 Operator 为中心,Operator 的边界过于清晰,因此导致数据在 Operator 之间传递(从 CPU 寄存器转移到内存)产生额外的内存带宽开销,无法做到 Data Locality 最大化,所以执行需要从以 Operator 为中心切换到以数据为中心,尽量让数据在寄存器中保存更长时间,确保 Data Locality 最大化。进一步的,Hyper 将操作系统的 NUMA 调度框架引入了数据库的查询执行调度[2],为 Push 模型实现了 parallelism-aware(就是对并行更友好):
- 采用 Pipeline 来组合算子,自底而上 Push 调度。当一个任务执行结束时,它会通知调度器将后序任务加入到任务队列中,每个数据块的单位被称为 Morsel 。一个 Morsel 大约包含 10000 行数据。查询任务的执行单位是处理一个 Morsel 。
- 优先将一个内核上的任务产生的后序任务调度在同一个内核上,避免了在内核间进行数据通信的开销。
- 当一个内核空闲时,它有能力从其他内核“偷取”一个任务来执行(Work Stealing),这虽然有时会增加一个数据传输的开销,但是却缓解了忙碌内核上任务的堆积,总体来说会加快任务的执行。
- 在内核空闲并可以偷取任务时,调度器并非立即满足空闲内核的要求,而是让它稍稍等待一段时间。在这段时间里,如果忙碌内核可以完成自己的任务,那么跨内核调度就可以被避免。
以多表 Join 为例:
SELECT ...
FROM S
JOIN R USING A
JOIN T USING B;
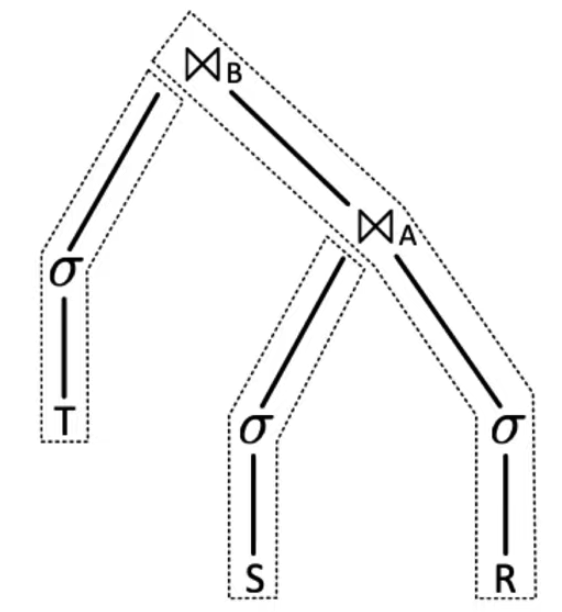
该查询由多个 Pipeline 组合而成,Pipeline 之间需要并行,Pipeline 内部也要并行。实际中并行的控制只需要在 Pipeline 的端点即可,例如上图中,中间的过滤等算子,本身无需考虑并行,因为源头的 TableScan 扫描会 Push 数据给它,而 Pipeline 的 Sink 是 Hash Join ,它的 Hashtable Build 阶段需要 parallelism-aware ,但 Probe 阶段无需这样。以 Push 为基础控制 Pipeline 的 parallelism-aware ,从技术上更加容易做到。
Push 模型实现 parallelism-aware 相对容易,那么为什么 Pull 模型实现 parallelism-aware 就不太容易呢?由于是自顶而下来调度而非数据驱动,因此一个直接的想法是划定分区,然后由优化器根据分区制定物理计划,不同分区的物理计划并行执行。这样容易导致一个问题就是让查询计划更加复杂(引入更多分区),而且并不容易做到负载的自动均衡,具体来说:对输入数据进行分区时,经过一些 Operator(如 Filter)后,不同分区保留下来的数据量区别很大,因此后续的算子执行就会面临数据倾斜问题。此外,不同的 CPU 处理同样数据量所花费的时间也并不一定相同,它会受到环境干扰、任务调度、阻塞、错误等原因减慢甚至中止相应,因此也会拖慢整体执行的效率。
Hyper 的 Push 模型是在 2011 年提出的,在这之前的 SQL 引擎,大都采用基于火山的 Pull 模型。已知基于 Push 构建的有 Presto ,Snowflake ,Hyper ,QuickStep ,HANA ,DuckDB(在 2021 年 10 月从 Pull 模型切换到了 Push 模型(详见参考文献[4]),Starrocks 等。ClickHouse 是个异类,在它自己的 Meetup 材料中,宣称自己是 Pull 和 Push 的组合,其中查询是采用了 Pull 模型。并且,在它的代码中,也一样是采用 Pull 字眼,作为查询调度核心驱动——PullingAsyncPipelineExecutor 。在通过 AST 生成 QueryPlan(逻辑计划)后,经过一些 RBO 优化,ClickHouse 将 QueryPlan 按照后序遍历的方式将其转化为 Pipeline ,这种方式生成的 Pipeline ,跟 Push 模型是很像的,因为 Pipeline 的每个 Operator(ClickHouse 定义叫 Processor),都有输入和输出,Operator 从输入将数据 Pull 过来,完成处理后,再 Push 给 Pipeline 的下一级 Operator 。因此,ClickHouse 并不是传统的火山 Pull 模型实现,而是从查询计划树生成 Pipeline 执行计划。从火山 Pull 模型的 Plan Tree 生成 Pipeline 的方法是后序遍历,从没有 Children 的 Node 开始构建第一个 Pipeline ,这是 Push 模型中生成 Pipeline Operator 的标准做法:
QueryPipelinePtr QueryPlan::buildQueryPipeline(...)
{
struct Frame
{
Node * node = {};
QueryPipelines pipelines = {};
};
QueryPipelinePtr last_pipeline;
std::stack<Frame> stack;
stack.push(Frame{.node = root});
while (!stack.empty())
{
auto & frame = stack.top();
if (last_pipeline)
{
frame.pipelines.emplace_back(std::move(last_pipeline));
last_pipeline = nullptr;
}
size_t next_child = frame.pipelines.size();
if (next_child == frame.node->children.size())
{
last_pipeline = frame.node->step->updatePipeline(std::move(frame.pipelines), build_pipeline_settings);
stack.pop();
}
else
stack.push(Frame{.node = frame.node->children[next_child]});
}
return last_pipeline;
}
Pipeline 调度
接下来是 Pipeline 调度,首先 PullingAsyncPipelineExecutor::pull 从 Pipeline 中拉取数据:
PullingAsyncPipelineExecutor executor(pipeline);
Block block;
while (executor.pull(block, ...))
{
if (isQueryCancelled())
{
executor.cancel();
break;
}
if (block)
{
if (!state.io.null_format)
sendData(block);
}
sendData({});
}
pull 调用的时候从 thread_group 选择线程,然后 data.executor->execute(num_threads)执行 PipelineExecutor ,num_threads 表示并行线程数。接下来 PipelineExecutor 将 Pipeline 转化为执行图 ExecutingGraph 。Pipeline 是逻辑结构,并不关心如何执行,ExecutingGraph 则是物理调度执行的参照。ExecutingGraph 通过 Pipeline Operator 的 InputPort 和 OutputPort 转换为 Edge ,用 Edge 把 2 个 Operator 连接起来,Operator 就是图的 Node 。随后就是 PipelineExecutor::execute 通过 ExecutingGraph 对 Pipeline 调度,这个函数主要作用是通过 task_queue 中 pop 出执行计划的 ExecutingGraph::Node 来调度任务。调度时,线程会不停遍历 ExecutingGraph ,根据 Operator 的执行状态进行调度执行,直到所有的 Operator 都到达Finished状态。调度器初始化,是挑选 ExecutingGraph 中所有没有 OutPort 的 Node 启动的,因此,控制流是从 Pipeline 的 Sink Node 发出的,递归调用 prepareProcessor ,这区别于 Push 模型的控制流从 Source Node 开始逐级向上。除了控制流向的不同,这个 Pipeline Operator 跟 Push 完全一样,因此也有人将 ClickHouse 归入 Push 模型中,毕竟,在很多文献的上下文,Push 等同于 Pipeline Operator ,Pull 等同于火山。Pipeline 和 ExecutingGraph 的对应如图所示(在 ClickHouse 中,Operator=Processor=Transformer):
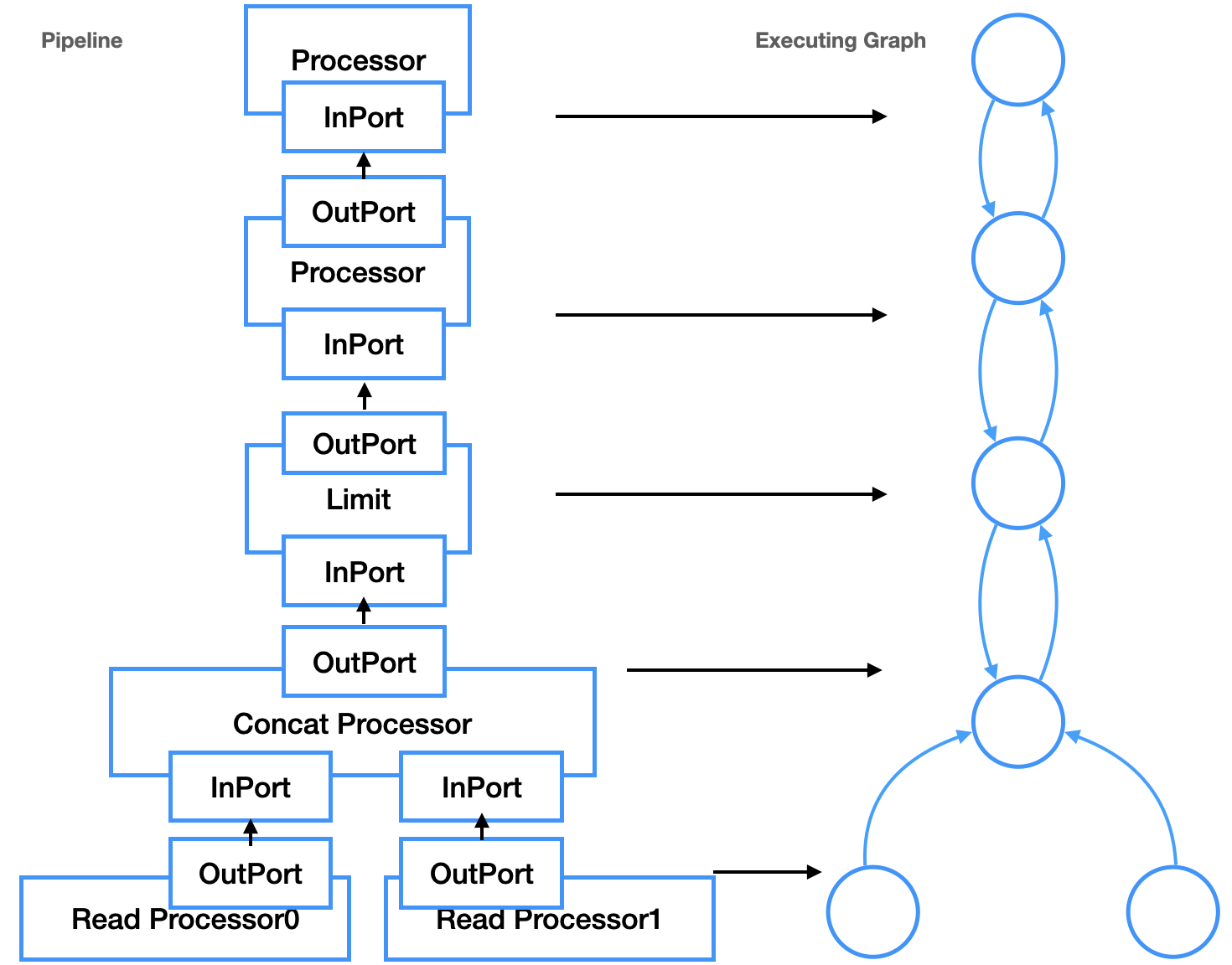
因此,Push 模型是 parallelism-aware 的,本质上需要设计工作良好的调度器,来控制数据流和并行度。除了上述的优点,朴素的 Push 模型也存在一些缺点:处理 Limit 和 Merge Join 有一些困难(详见参考文献[1]),对于前者来说,Operator 不容易控制数据何时不再由源 Operator 产生,这样就会产生一些永远不会被使用的元素。对于后者来说,由于 Merge Join Operator 无法当前由哪个源 Operator 产生下一个数据 Tuple ,所以 Merge Join 无法进行流水线处理,因此至少对其中一个源 Operator 要打破流水线(Pipeline Breaker),需要对其进行物化操作。这两个问题,其本质依然是 Push 模型下的 Pipeline 调度问题:消费者如何控制生产者,除了 Limit 和 Merge Join 之外,其他的操作,例如终止正在进行的查询,也是一样的情况。正如通过分离查询计划树和 Pipeline 使得 Pull 模型可以 parallelism-aware 之外,Push 模型在工程实现上也并没有必要完全如同论文所描述,只能控制 Pipeline 的源头。通过引入 ClickHouse task_queue 类似的机制,Push 模型同样可以做到对源 Operator 的逐级控制。
MatrixOne 的 Pipeline 实现
MatrixOne 基于 Golang 开发,因此直接利用 Go 语言特性实现了 Push 模型:利用 channel 作为阻塞消息队列,通知生产者。查询计划由多个 Operator 构成,pipeline 是包含多个 Operator 的执行序列。Operator 代表一个具体的操作,比如典型的过滤,投影,hash build 和 hash probe 都可以。对于一个查询计划来说,首先需要确定使用多少个 pipeline ,使用多少个 cpu ,每个 cpu 跑哪些 pipeline 。具体实现中,借助于 Golang 语言的特性:一个 pipeline 对应一个 goroutine ,pipeline 之间通过 channel(无 Buffer)传递数据,pipeline 的调度也是通过 channel 来驱动。举例如下:
Connector Operator
func Call(proc *process.Process, arg interface{}) (bool, error) {
...
if inputBatch == nil {
select {
case <-reg.Ctx.Done():
process.FreeRegisters(proc)
return true, nil
case reg.Ch <- inputBatch:
return false, nil
}
}
}
由于是 Push 模型,因此一个查询计划是通过 Producer Pipeline 触发整个流程的,非生产者的 Pipeline ,没有接收到数据,是不会运行。Producer Pipeline 在启动后,就会尝试读取数据,然后通过 channel 将数据发送给另一个 Pipeline ,Producer Pipeline 在启动后就会不停的读取数据,只存在两种情况会退出:
- 数据读取完
- 发生错误
当非生产者的 pipeline 没有从 channel 读取 Producer Pipeline 推送的数据时,Producer Pipeline 会阻塞。非生产者的 Pipeline 在启动后并不会立刻执行,除非 Producer Pipeline 在 channel 中放置了数据。Pipeline 在启动后会在以下两种情况退出:
- 从 channel 中接受到了退出信息
- 发生错误
MatrixOne 会根据数据的分布将 Producer Pipeline 分配到具体的节点。在特定的节点接收到 Producer Pipeline 后会根据当前机器和查询计划的情况(目前是获取机器的核数)来派生多个 Producer pipeline 。其余 Pipeline 的并行度,则是在接受数据的时候确定其并行度。
下边先看一个简单查询:
select * from R where a > 1 limit 10
这个查询存在 Limit Operator ,意味着存在上文所述的 Cancel ,Limit ,Merge Join 等 Pipeline 的终止条件。该查询的 Pipeline 如下所示,它在 2 个 Core 上并行执行。

由于 Limit 的存在,Pipeline 引入了 Merge Operator ,与此同时跟调度相关的问题是:
- Merge 不能无限制地接受多个 Pipeline 的数据,Merge 需要根据内存大小通过 Connector 向上游发送 channel 停止数据读取。
- Pipeline 数目根据 CPU 数量动态决定,当 Pipeline 不再推送数据时,查询自然终止,因此 Merge 需要标志是否已经传输结束。
再看一个复杂一些的例子,tpch-q3:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'HOUSEHOLD'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-29'
and l_shipdate > date '1995-03-29'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit 10
假设查询计划如下:
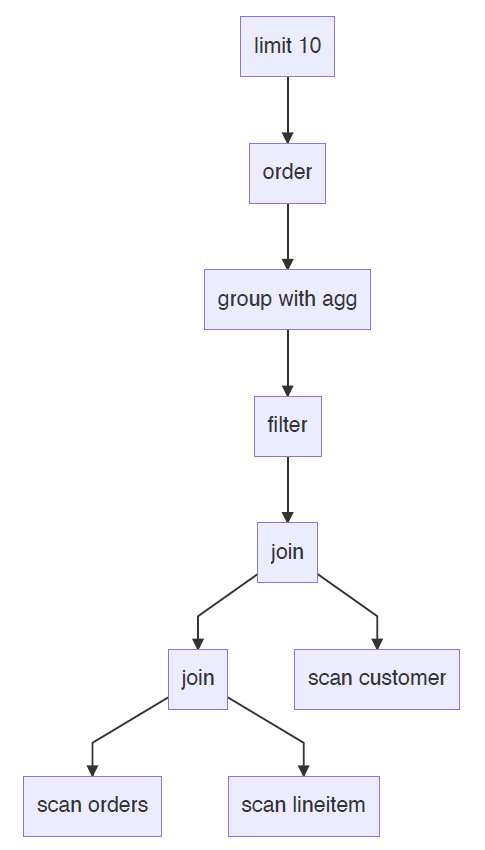
假设三张表的数据均匀分布在两个节点 node0 和 node1 上,那么对应的 Pipeline 如下:
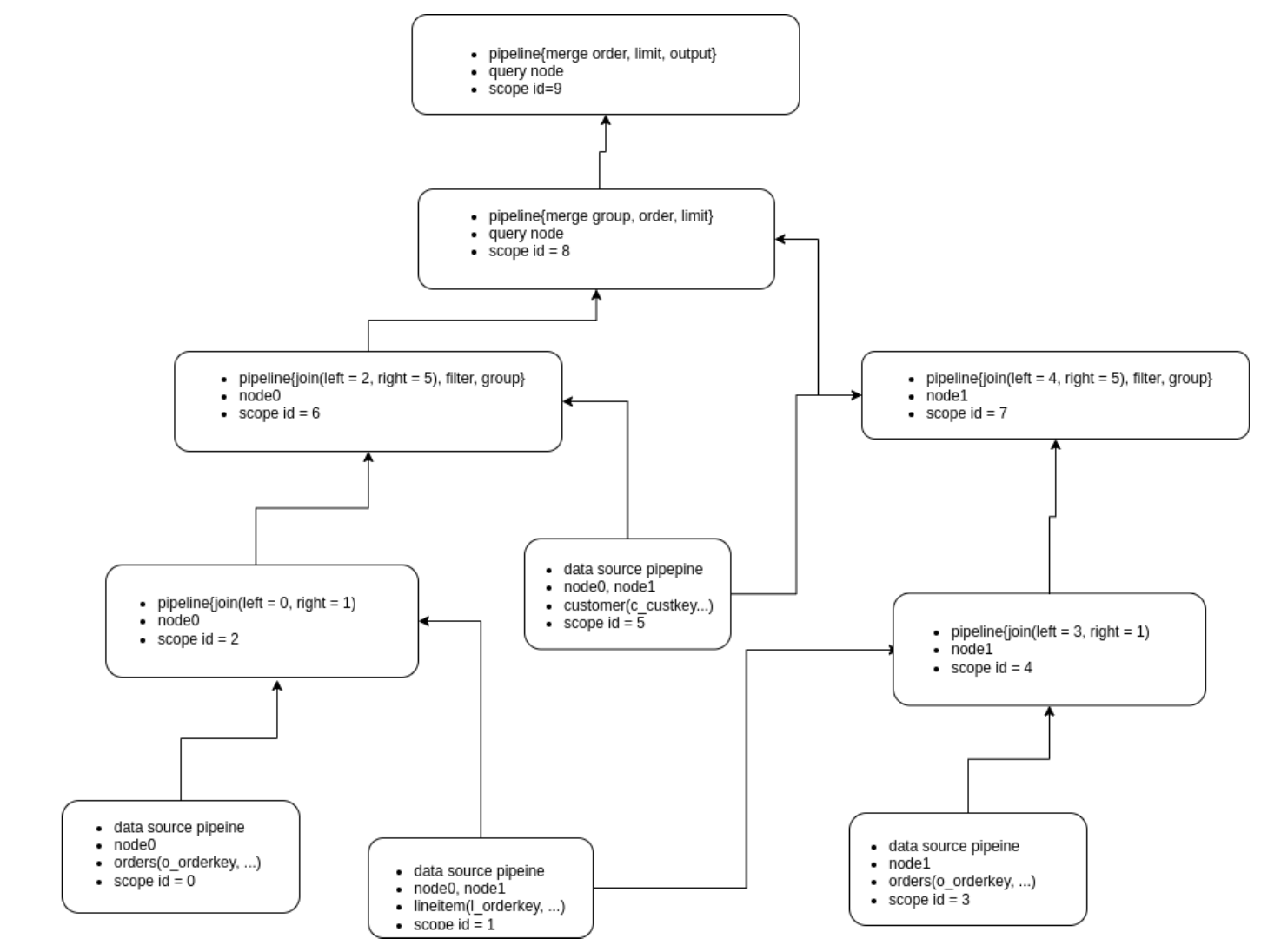
采用 Push 模型的还有一个潜在优点在于,它跟流计算的 Data Flow 范式(如 Flink)容易保持一致。FlinkSQL 会把查询计划的每个 Operator 转为流式 Operator ,流式 Operator 会将每个 Operator 的计算结果的更新传给下一个 Operator ,这从逻辑上跟 Push 模型是一致的。对于打算在数据库内部实现流引擎的 MatrixOne 来说,这是一个逻辑复用的地方,当然,流引擎远不是只依靠 Push 模型就可以解决的,这超出了本文讨论的范畴。采用 Push 模型最后一个潜在优点是,它和查询编译 Codegen 是天然组合,目前 MatrixOne 并没有实现 Codegen ,故而这也超出了本文讨论的范畴。
当前的 MatrixOne ,实现了基本的基于 Push 模型的计算并行调度,在未来,还会在多方面上进行改进,比如针对多查询的混合并发与并行的任务调度,比如当算子因为内存不足需要进行 Spill 处理时,也需要 Pipeline 的调度能够感知并有效处理,既能完成任务,还能最小化 IO 开销,这里边会有很多非常有意思的工作。也欢迎对这方面感兴趣的同学跟我们一起探讨这些层面上的创新。所以,Push 还是 Pull ,这是个问题么?好像是,好像也不是,一切以实际效果为着眼点,并非简单地非黑既白,这代表了一种计算并行调度的思维方式。
参考文献
[1] Shaikhha, Amir and Dashti, Mohammad and Koch, Christoph, Push versus pull-based loop fusion in query engines, Journal of Functional Programming, Cambridge University Press, 2018
[2] Leis, Viktor and Boncz, Peter and Kemper, Alfons and Neumann, Thomas, Morsel-driven parallelism: A NUMA-aware query evaluation framework for the many-core age, SIGMOD 2014
[3] Thomas Neumann, Efficiently compiling efficient query plans for modern hardware, VLDB 2011
[4] https://github.com/duckdb/duckdb/pull/2393
MatrixOne 社区
对 MatrixOne 有兴趣的话可以关注矩阵起源公众号或者加入 MatrixOne 社群。
 微信公众号 矩阵起源
微信公众号 矩阵起源
 MatrixOne 社区群 技术交流
MatrixOne 社区群 技术交流
目前尚无回复