
这是一个创建于 1240 天前的主题,其中的信息可能已经有所发展或是发生改变。
把 Tesseract.js 包装成直接能用的网站了,全程在你的浏览器中识别,不需要上传。
个人主要用来识别测试反馈的截图, 抓里面的 TraceID 和接口调用参数,使用体验还不错。
对英文的识别效果还可以,中文的有点菜。
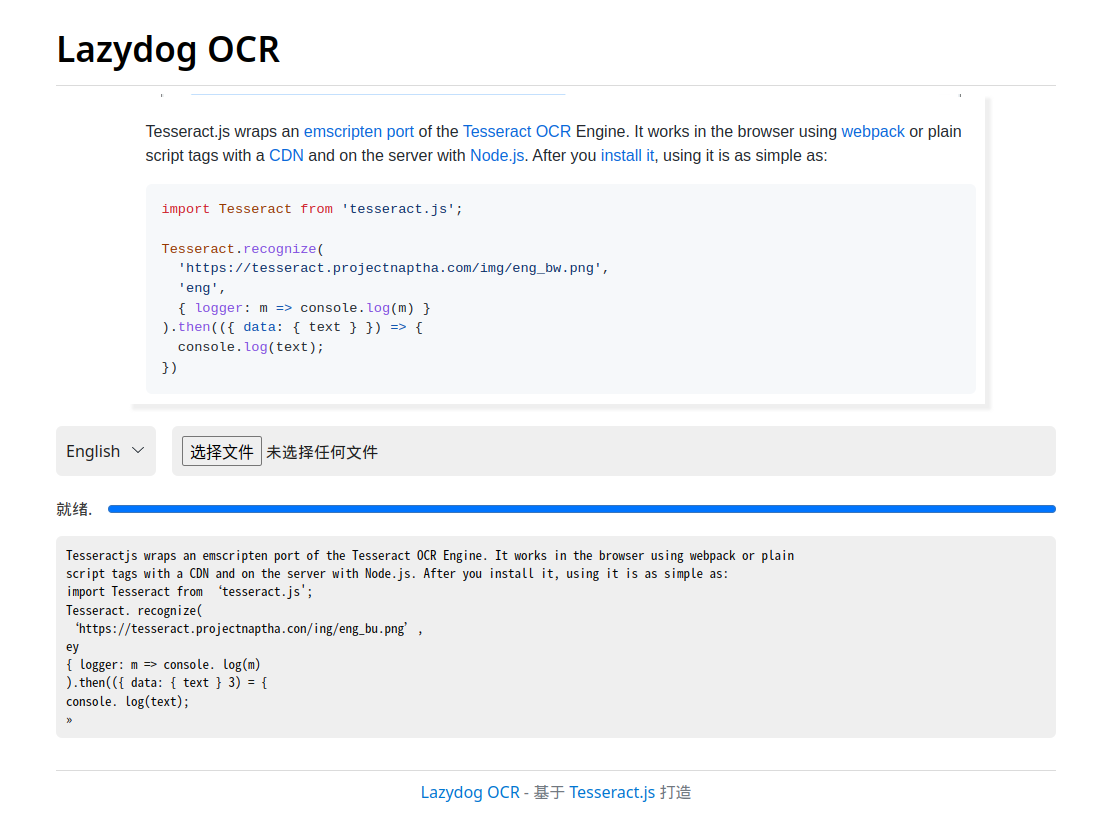
在线体验版: https://ocr.zjyl1994.com/
Github: https://github.com/zjyl1994/lazydogocr
注意:需要你的浏览器支持 WASM ,在线体验版部署在 CF Pages 上,加载训练数据需要 10 多 MB ,可能不会太快。
 |
1
jeesk 2022 年 9 月 25 日 via Android
10s 都识别不出 😂
|

 |
4
Kiriya 2022 年 9 月 25 日
可以考虑打包成本地应用😁
|
 |
5
HugoChao 2022 年 9 月 25 日
用了一下 感觉不错
|
 |
6
mozila 2022 年 9 月 25 日
先 m
|
 |
7
HiCoder 2022 年 9 月 25 日
试了下,不错
|
 |
9
subframe75361 2022 年 9 月 26 日
好东西,可以考虑做个 pwa ?
|
 |
10
ShuaiYH 2022 年 9 月 26 日
个人感觉这个库识别率有点低,特别是对于手写的
|
 |
11
Aying 2022 年 9 月 26 日
|
 |
12
villivateur 2022 年 9 月 26 日
中文识别,为什么每个字之间都会多出一个空格?
|
 |
13
vantis 2022 年 9 月 26 日
中文可以试试 paddle 阿里云有一件部署的 感觉识别率挺高
我是本地用 python 跑的 搭配 Alfred workflow 除了慢都挺好…… |
 |
14
vtwoextb 2022 年 9 月 27 日
现在开源的深度学习框架很多都包括 OCR ,这东西比较费资源
|
 |
15
marvinemao 2022 年 9 月 27 日
感觉不错
|
 |
16
macy 2022 年 9 月 27 日
基于这个库做过一个 pdf 识别的软件,除了慢点,效果还好,可以做精准识别,配置截图,将大图截取指定部分,会快很多,也会准确一些
|
 |
17
caomingjun 2022 年 9 月 28 日
如果只开发 Windows 应用,可以试试自带的 OCR: https://learn.microsoft.com/en-us/uwp/api/Windows.Media.Ocr?view=winrt-22621
|
 |
18
bianz103 2022 年 10 月 5 日
昨天把 paddleocr 整合到本地软件 verycapture 了,识别速度大概 8 秒左右,建议楼主可以试试
|

 |
20
Endocryne 2023 年 10 月 12 日
识别率不是很理想
|