
ACG2vec 系列之 DanbooruCLIP——二次元数据集微调的 CLIP 模型
OysterQAQ · OysterQAQ · 2023 年 5 月 19 日 · 3902 次点击这是一个创建于 1010 天前的主题,其中的信息可能已经有所发展或是发生改变。
ACG2vec 系列之 DanbooruCLIP——二次元数据集微调的 CLIP 模型
介绍
Huggingface 在线体验: https://huggingface.co/OysterQAQ/DanbooruCLIP
github 主仓库地址( pt 模型文件可以在 release 下载): https://github.com/OysterQAQ/ACG2vec
使用 danburoo2021 数据集对 clip ( ViT-L/14 )模型进行微调。
0-3 epoch 学习率为 4e-6 ,权重衰减为 1e-3
4-8 epoch 学习率为 1e-6 ,权重衰减为 1e-3
标签预处理过程:
for i in range(length):
# 加载并且缩放图片
if not is_image(data_from_db.path[i]):
continue
try:
img = self.preprocess(
Image.open(data_from_db.path[i].replace("./", "/mnt/lvm/danbooru2021/danbooru2021/")))
except Exception as e:
#print(e)
continue
# 处理标签
tags = json.loads(data_from_db.tags[i])
# 优先选择人物和作品标签
category_group = {}
for tag in tags:
category_group.setdefault(tag["category"], []).append(tag)
# category_group=groupby(tags, key=lambda x: (x["category"]))
character_list = category_group[4] if 4 in category_group else []
# 作品需要过滤以 bad 开头的
work_list = list(filter(
lambda e:
e["name"] != "original"
, category_group[3])) if 3 in category_group else []
# work_list= category_group[5] if 5 in category_group else []
general_list = category_group[0] if 0 in category_group else []
caption = ""
caption_2 = None
for character in character_list:
if len(work_list) != 0:
# 去除括号内作品内容
character["name"] = re.sub(u"\\(.*?\\)", "", character["name"])
caption += character["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
caption += " "
if len(work_list) != 0:
caption += "from "
for work in work_list:
caption += work["name"].replace("_", " ")
caption += " "
# 普通标签
if len(general_list) != 0:
caption += "with "
if len(general_list) > 20:
general_list_1 = general_list[:int(len(general_list) / 2)]
general_list_2 = general_list[int(len(general_list) / 2):]
caption_2 = caption
for general in general_list_1:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption_2 += general["name"].replace("_", " ")
caption_2 += ","
caption_2 = caption_2[:-1]
for general in general_list_2:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
else:
for general in general_list:
# 如果标签数据目大于 20 则拆分成两个 caption
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
# 标签汇总成语句
# tokenize 语句
# 返回
# 过长截断 不行的话用 huggingface 的
text_1 = clip.tokenize(texts=caption, truncate=True)
text_2= None
if caption_2 is not None:
text_2 = clip.tokenize(texts=caption_2, truncate=True)
# 处理逻辑
# print(img)
yield img, text_1[0]
if text_2 is not None:
yield img, text_2[0]
预览
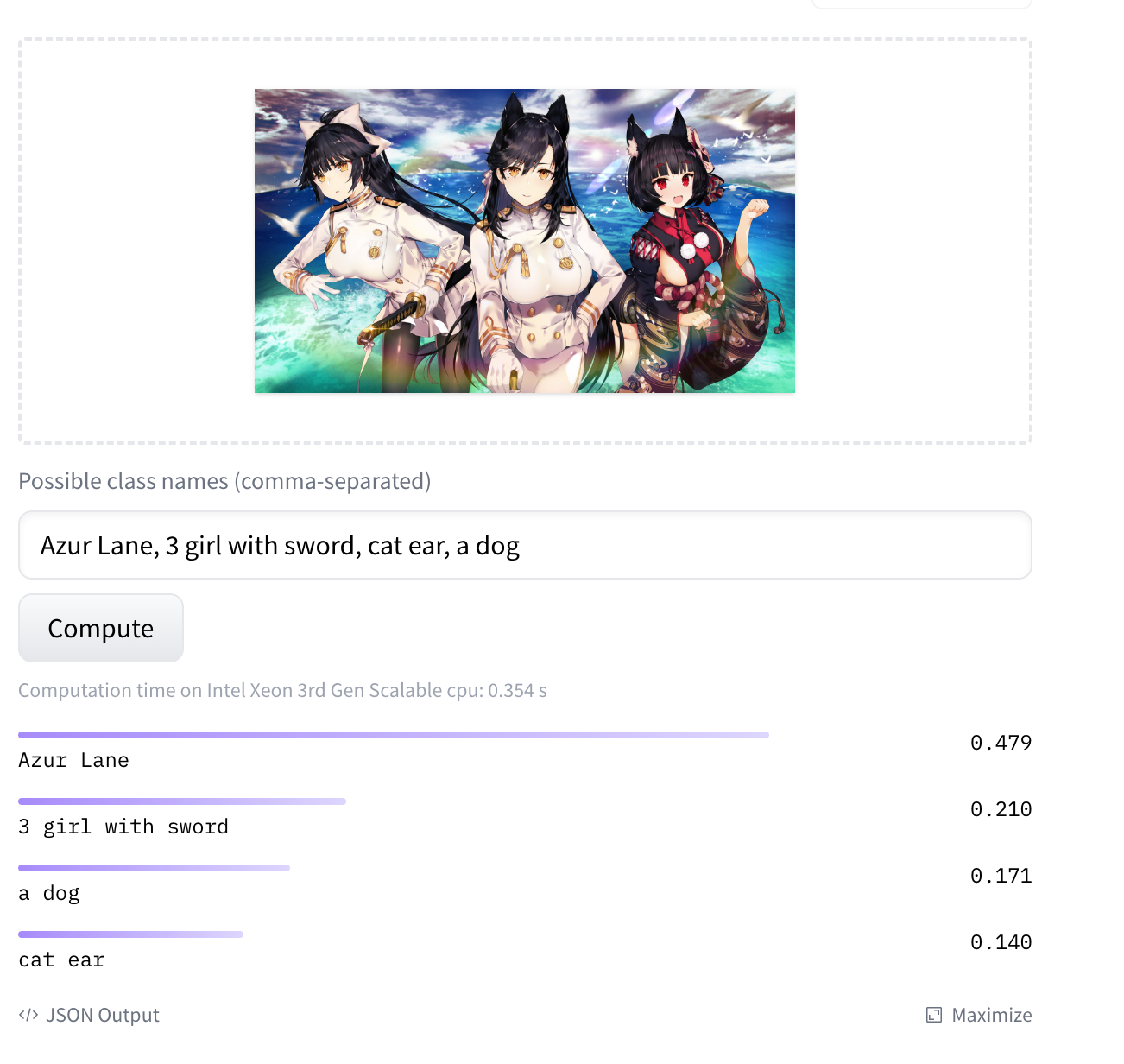
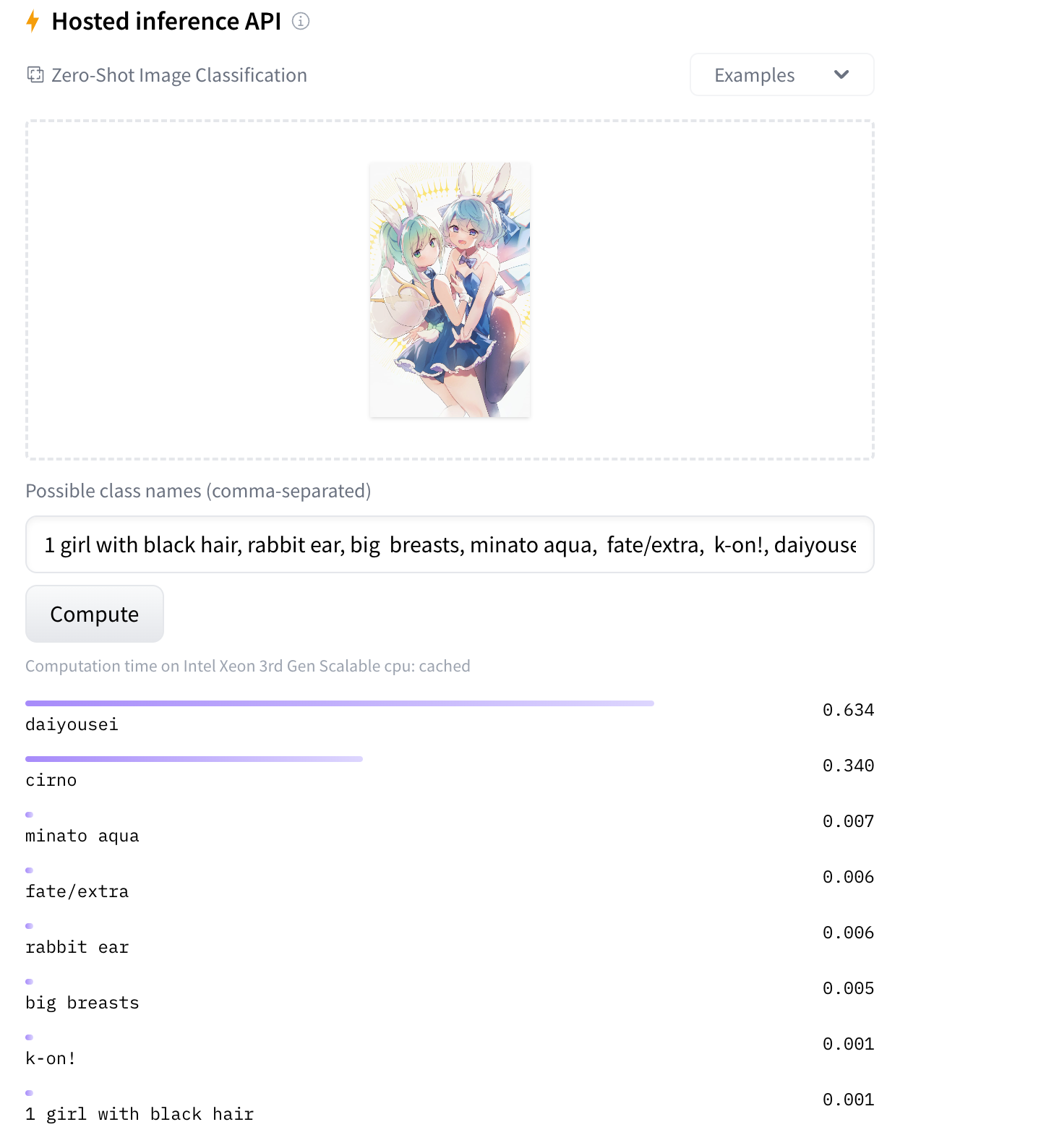
 |
1
tyzandhr 2023 年 5 月 19 日 via Android
你们搞得这个呀,一颗赛艇
|
 |
2
OysterQAQ OP 没有成品应用好像大伙都不感兴趣 后面会放出以文搜图(动漫插图)的应用 api
|
 |
3
mogita 2023 年 5 月 19 日
挽尊...还折了个置顶 😄
|
 |
5
cest 2023 年 5 月 19 日
danbooru 的已经有了
原来是 tensorflow 的 a1111 port 到 pytorch model 要能 tag 当季的才好吸睛吧 或是出个 frontend 可以一次用各种 model 来 tag 再整理出最最可能的 tag |
|
6
OysterQAQ OP @cest deepdanbooru 是做了多标签多分类,标签有限制数目,后续我会在千万张 pixiv 图片上提供文本到图像的检索服务,可以解决一些 pixiv 本身图片 tag 质量差的问题
|
 |
7
oldshensheep 2023 年 5 月 20 日
搞个逆向 StableDiffusion ,输入图片生成 prompt
|
|
8
OysterQAQ OP @oldshensheep blip 就可以做到
|
 |
9
chenY520 2023 年 5 月 21 日 via iPhone
没找到有关多模态的帖子,来这里问一下。多模态模型训练有什么最低配置嘛?
|
|
10
OysterQAQ OP @chenY520 moco 那种队列负样本方式的话,8 张 a100 可以跑完整的训练,微调的话,我是用一张 3090 就完成了
|
 |
11
lopssh 2023 年 5 月 21 日 via Android
谢谢
|
 |
12
graetdk 2023 年 5 月 21 日
太强了,大佬是研究这个领域的吗
|
|
13
OysterQAQ OP @graetdk 哈哈 不是大佬 我们之前还聊过呢 你应该还有我 qq 不算专业研究 cv 的 在读研 方向是深度学习的推荐系统 这些算是 side project
|
 |
15
Thiece 2023 年 5 月 22 日
看见 tensorflow 就失去兴趣了
|
|
16
OysterQAQ OP @Thiece pytorch 和 tf 都有 里面有 tf 的代码只是我需要本地 tf-serving 部署才转换权重的 本身微调训练是 pytorch clip 本身也是 pytorch 写的
|
 |
17
ikaros 2023 年 5 月 24 日
请问一下第一张图里 a dog 在哪里?
|