
这是一个创建于 1837 天前的主题,其中的信息可能已经有所发展或是发生改变。
作者介绍:
康文权,马上消费金融总账高级研发工程师。
李银龙,原腾讯云运维工程师,马上消费金融容器云 TiDB 负责人,西南区 TUG Leader。
背景介绍
马上消费金融于 2015 年 6 月营业,截止到 2020 年 1 月,历经 4 年多风雨,总注册用户数 8000 万,活跃用户数 2500 万,累计放贷 2900 多亿元人民币。公司于 2018 年 6 月增资到 40 亿,成为内资第一大的消费金融公司。
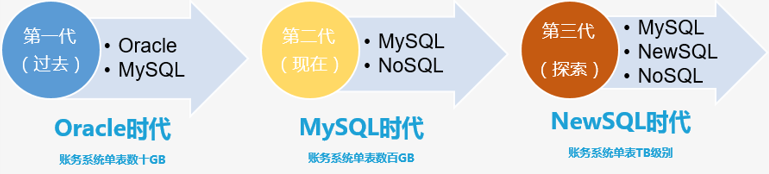
在业务爆发式增长的 4 年多里,马上消费金融的数据库经历了从单表数十 GB 到数百 GB 的过程,单表的数据量正在往 TB 级别演进。基于数据量的升级变迁,我们的数据库也经历了 2 次架构迭代,并在探索
第三代数据库架构:
- 第一代数据库架构——核心系统以 Oracle 为主,MySQL 为辅的时代。
- 第一代数据库架构——核心系统以 Oracle 为主,MySQL 为辅的时代。
- 第三代数据库架构——核心系统以 MySQL 结合 NewSQL 为主,NewSQL、MySQL、NoSQL 并存的时代。
马上金融第二代数据库架构痛点
海量数据 OLTP 场景需求痛点
截止目前账务系统的核心表累计数据量已达到单表 15 亿行以上,还在高速增长中。监管要求金融行业历史数据至少保留 5 年以上。这给数据库系统带来了巨大挑战:
-
海量的历史交易与账务数据堆积在 MySQL 数据库中,使数据库臃肿不堪,维护困难(在线 DDL 变更、数据迁移、磁盘容量瓶颈、磁盘 IO 瓶颈等)。
-
用户对历史交易订单的查询( OLTP 场景)是必备功能,这些海量的历史数据会根据用户需求通过 Web 页面、APP 终端等渠道进行实时查询(内部、外部用户)。此场景决定了不能通过传统的离线大数据方案来满足需求。需要一种偏向于前台、中台的数据治理方案。
传统分库分表解决方案痛点
根据马上金融的经验,MySQL 单表在 5000 万行以内时,性能较好,单表超过 5000 万行后,数据库性能、可维护性都会极剧下降。当我们的核心账务系统数据库单表超过 100GB 后(截止 2018 年 10 月该表累计已达到 528GB ),经技术架构团队、业务需求团队联合调研后,选择了 sharding-jdbc 作为分库分表的技术方案。
此方案的优点非常明显,列举如下:
-
将大表拆分成小表,单表数据量控制在 5000 万行以内,使 MySQL 性能稳定可控。
-
将单张大表拆分成小表后,能水平扩展,通过部署到多台服务器,提升整个集群的 QPS、TPS、latency 等数据库服务指标。
但是,此方案的缺点也非常明显:
-
分表跨实例后,产生分布式事务管理难题,一旦数据库服务器宕机,有事务不一致风险。
-
分表后,对 SQL 语句有一定限制,对业务方功能需求大打折扣。尤其对于实时报表统计类需求,限制非常之大。事实上,报表大多都是提供给高层领导使用的,其重要性不言而喻。
-
分表后,需要维护的对象呈指数增长( MySQL 实例数、需要执行的 SQL 变更数量等)。
传统 MySQL 在线 DDL 痛点
对超过账务系统的 528GB 大表分库表成 16 张表之后,每张表有 33GB,仍然是大表。我们采用了 gh-ost 工具进行加字段 DDL 操作,但是,业务仍然会有轻微感知。因此,必须要将大表的 DDL 操作放到凌晨来做,对业务的 7*24 小时服务有较大限制。
原生 MySQL 的 HA 机制不完善痛点
MySQL 的集群基于 Binlog 主从异步复制来做,切集群主从角色以 instance 为单位,非常僵化。一旦主库出现故障,需要人工重建 MySQL 集群主从关系(也可以把人工操作落地成程序,比如 MHA 方案),截止目前( 2020 年 1 月)原生 MySQL 仍然没有成熟可靠基于 Binlog 异步复制的 HA 方案。基于 Binlog 异步复制的 MySQL 主从架构实现金融级高可用有其本质困难。
马上金融 NewSQL 技术选型
基于马上金融第二代数据库架构的核心痛点,我们需要探索新的数据库技术方案来应对业务爆发式增长所带来的挑战,为业务提供更好的数据库服务支撑。
恰逢 NewSQL 愈渐火热,引起了我们的极大关注。NewSQL 技术有如下显著特点:
-
无限水平扩展能力
-
在线 DDL 操作不锁表
-
分布式强一致性,确保金融数据 100% 安全
-
完整的分布式事务处理能力与 ACID 特性
在账务系统研发团队、公共平台研发团队、DBA 团队等联合推动下,我们开始对 NewSQL 技术进行调研选型。
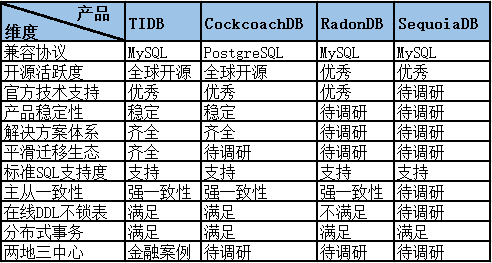
在 GitHub 的活跃度及社区贡献者方面,TiDB 与 CockcoachDB(CRDB) 都是国际化的全球开源级项目,是 NewSQL 行业中的代表性产品。
由于马上金融的应用绝大部分对 MySQL 依赖较高,在协议兼容性方面,我们毫无疑问地将 MySQL 兼容性列为必选项。
TiDB 从项目发起之初就将 MySQL 协议兼容性列为最 basic 的战略目标之一。而 CRDB 在项目发起之初,考虑的是兼容 PostgreSQL 协议。
基于此,我们优先选择了 TiDB 技术产品。
马上金融实践案例分享(两则)
案例一:核心账务系统归档场景
马上消费金融账务系统归档项目是公司第一个持续实践 TiDB 的项目,也是第一个对 NewSQL 技术提出迫切需求的项目,上线后 TiDB 架构如下:
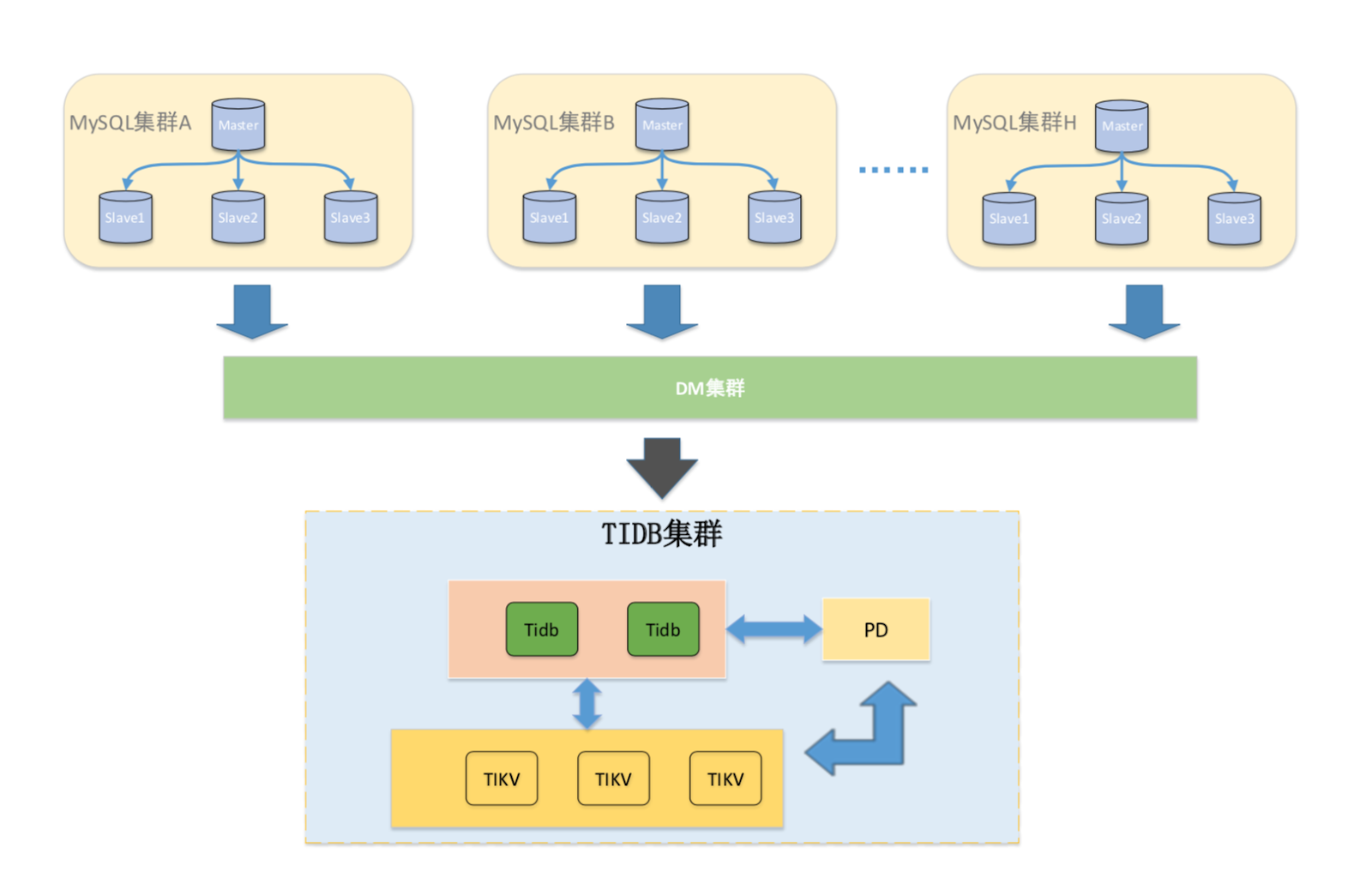
上游分库分表的 8 套 MySQL 集群通过 DM 聚合到一套 TiDB 里,TiDB 对外提供历史归档大表查询服务。
应用架构关键机制:
-
读写分离。通过 sharding-jdbc 实现应用程序读写分离,将历史数据查询请求分发到 TiDB 集群。
-
熔断机制。应用架构设计了熔断机制,当请求 TiDB 超时或者失败后,会自动将请求重新转发到 MySQL,恢复业务。
通过熔断机制可确保万一 TiDB 出现异常时,能快速恢复业务,确保业务的可用性。
账务 TiDB 集群每天业务高峰期将会承载约 1.3 万 QPS 的请求量(如下图所示),在做活动期间,请求量能冲击到近 3 万 QPS。
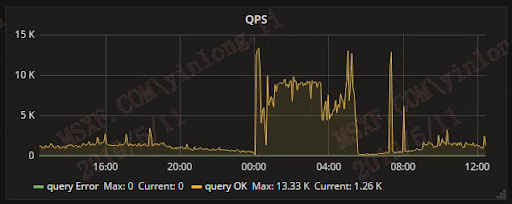
经过接近 1 年的不断优化提升,TiDB 集群表现越来越稳定,大部分请求能在 50ms 内返回:
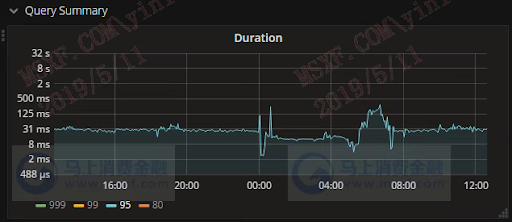
研发同事对 TiDB 的 Latency 与 TPS 的性能表现比较满意。
在 2019 年 4 月,账务系统 TiDB 项目已将 MySQL 数据库 2018 年以前的历史数据删除。极大地降低了账务系统 8 套 MySQL 数据库集群的 IO 压力。这部分历史数据仅保存在 TiDB 集群内,对业务提供实时查询支持。
案例二:总账跑批业务场景
马上消费金融总账项目是公司第一个完全运行在 TiDB 的项目,也是第一个从项目上线之初就放弃 MySQL,坚定不移选择 TiDB 的项目。
总账项目部分模块关键流程示意图如下:
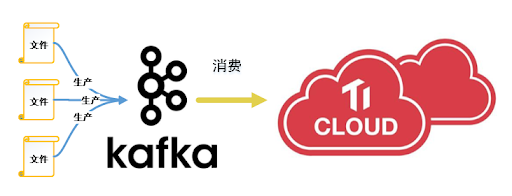
马上消费金融总账项目是公司第一个完全运行在 TiDB 的项目,也是第一个从项目上线之初就放弃 MySQL,坚定不移选择 TiDB 的项目。
总账项目部分模块关键流程示意图如下:
-
数据量基数大。总账项目吸纳了公司核心账务系统以及其他关联系统的所有数据,数据基数非常巨大,要求至少 10TB+ 空间,未来 2 年内可能会增长到 20TB 以上。这个基数 MySQL 难以承载。
-
每日批量时限短。总账项目服务于管理层,每月初呈现公司当月的营收核算等信息。在总账项目数据量基数巨大的前提下,日增量 5 亿到 10 亿,希望每天能在 3 个小时内完成跑批,用 MySQL 单实例跑不下来。而分库分表技术方案对于总账系统出报表需求又具备其客观难题。
TiDB 是分布式 NewSQL,计算与存储分离,且计算节点与存储节点都具备水平扩展能力,特别适用于总账项目的大数据量、大吞吐量、高并发量场景。
项目上线已稳定运行半年左右,目前集群规模如下:
-
8 TB+ 数据量
-
12 POD TiDB 节点
-
24 POD TiKV 节点
-
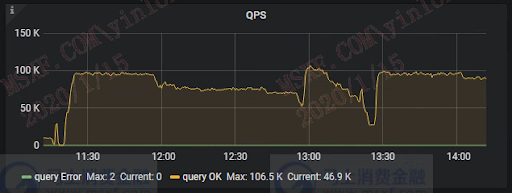
跑批期间峰值超过 10 万 QPS
总账项目目前完成了第二期开发,随着项目的继续发展,未来第三期的 ngls 正式接入后,数据量与并发量将再次成倍增长。
总账项目上线后,跑批期间 QPS 如下:
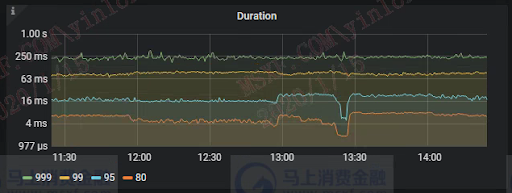
跑批期间的 SQL 响应时间如下:
跑批期间的 TiKV CPU 使用率如下:
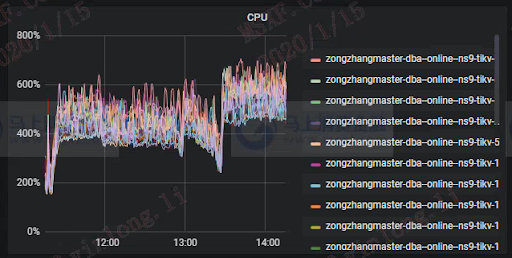
跑批期间事务量与性能如下:
![]()
马上金融 TiDB 经验总结分享
TiDB 切入点经验
TiDB 是一个新潮的 NewSQL 数据库。想要将 TiDB 运用到生产环境,解决 MySQL 数据库面临的历史难题(而不是把问题搞得更大),并不是一件简单的事情。
时至今日( 2020 年 1 月 14 日),TiDB 已经在数千家企业有实践经验,其中不乏大型银行核心系统 TiDB 实践经验。且 TiDB 3.0 GA 之后,TiDB 在性能、稳定性方面比起之前版本都有了很大的提升。
这意味着已经有数千家企业在向 PingCAP 官方反馈 TiDB 的各种问题并持续得到修复。在这样的背景下,TiDB 能在生产环境中稳定运行并持续为企业创造价值已是毋庸置疑。
对于企业而言,当前的关注焦点可能不再是 TiDB 是否稳定可靠,而是怎么才能快速获取到 TiDB 的最佳实践经验,将其纳入企业基础技术栈之内。
那么,如何才能快速实践 TiDB,积累到第一手经验,使企业尽快享受到 TiDB 带来的福利呢?
建议从两个方面切入:
-
选定一个归档项目着手尝试: 参考我们的账务系统 TiDB 归档技术方案作为企业的切入点。通过此方案,大家可以快速上手 TiDB,在技术风险可控的前提下积累到 TiDB 实践经验。
-
联系官方或者 TUG 组织获取资源:TiDB 是一个全新的分布式数据库,整个体系架构的相比于 MySQL 要复杂得多。而截止目前( 2020 年 1 月 14 日),TiDB 官方提供的文档相比 MySQL 等传统数据库要简陋得多。官方文档是入手 TiDB 的必读资料,但是,仅仅依靠官方文档是不充分的。最好能联系官方同学或者各地的 TUG 组织获得支持。
TiDB 服务器硬件实践经验
从我们过去近两年实践经验看,TiDB 是否能在生产环境运行稳定,硬件规划是至关重要的先决条件之一。其中,硬件规划最重要的环节包括两个:
-
**存储设备规划。**TiDB 官方建议使用 NVME 协议的 SSD,时至今日( 2020 年 1 月 14 日),主流的服务器 NVME 协议接口已不再是 pcie 口,而是 u.2 口。这个是大家都知道的,本无需赘言。真正需要关注的是 SSD 的品牌、型号。我们建议选择 Intel p4510 这一款 SSD,这款 SSD 的读 IOPS 理论值达到 60 万以上、写 IOPS 理论值达到 8 万以上,在生产实践对比结果来看,是 TiDB 的最佳搭档。
-
**网络设备规划。**服务器、交换机都采用万兆网卡,比较简单,但非常重要。
TiDB 相关软件实践经验
tidb-server 优化经验
tidb-server 可能发生性能异常的地方主要是 CBO 统计信息失效问题与索引设计不合理问题。这两个点并非 TiDB 独有的问题,MySQL、Oracle 等也有类似的问题。对于前者,建议对关键表定时做 analyze,以确保统计信息准确性。而索引相关的问题,根据常见的数据库优化技巧处理即可。从 3.0 版本开始,TiDB 支持 SQL 查询计划管理功能( SQL Plan Management ),对这类问题提供了另一套解决方案。
tikv-server 优化经验
TiKV 第一个最常见的问题是内存消耗过多被 OOM kill 的问题。TiDB 3.0 以后对 TiKV 内存配置做了优化,官方推荐将 block-cache-size 配置成 TiKV 实例占据总内存的 40%,我们在实践中发现,40% 的参数值在数据库压力极大的情况下仍然可能会出现 OOM 现象,需要基于 40% 继续往下调整才能找到与业务场景真正匹配的参数值。
TiKV 另外一个问题是乐观锁适配问题。Oracle、MySQL 采用悲观锁模型,事务在做变更之前需要获取到行锁,然后才能做变更,如果没有获取到行锁,则会排队等待。而 TiDB 则相反,采用乐观锁模型,先更新记录,在提交事务时,再做锁冲突检测,如果冲突了,则后提交事务的会话会报错 Write Conflict 错误引起应用程序异常。这个错误需要从 2 个方向进行处理。在 TiDB 3.0 版本下,默认关闭了事务提交重试功能,需要手工设置 tidb_disable_txn_auto_retry 参数,才能打开事务失败重试功能。另外,TiDB 的乐观锁模型决定了其不擅长处理事务冲突较大的场景,比如典型的“计数器”功能,这类场景最好将技术器功能放到第三方软件来实现会比较合适(比如 Redis )。另外,从 3.0 版本开始,TiDB 已经开始支持悲观锁功能,这个功能预计在 4.0 GA,我们也开始了这一块的测试工作。
DM 实践经验
到目前为止( 2020 年 1 月 14 日),DM 仍然没有发布高可用机制版本,官方正在紧锣密鼓实现高可用机制,我们建议将 TiDB 用做归档场景作为实践 TiDB 的起点,而不将其作为最终的目标。实践 TiDB 的目标是将 TiDB 作为对前台应用提供 OLTP 服务的数据库。
使用 DM 的关键是有效规避 MySQL 到 TiDB 同步的异常问题,使同步能持续稳定运行。对于刚接触 TiDB 的同学而言,建议从最简化的方式使用 DM:
-
保持 MySQL 到 TiDB 同步的逻辑结构一致。也就是说,MySQL 里的库表是什么样子,DM 同步到 TiDB 就是什么样子。不做分表聚合。分表聚合长期实时同步有其本质困难,不适合作为初学者的目标。
-
语法预验证确保兼容性。TiDB 与 MySQL 是“高度兼容”的,但没有人能承诺 100% 兼容(其他数据库也一样不敢夸口 100% 兼容 MySQL )。也就是说,如果一些生僻的 SQL 语句在 MySQL 上执行成功了,通过 DM 同步到 TiDB,可能会执行失败,引起同步中断异常。这类问题的最好解决方法是先将变更的 SQL 语句在测试环境 TiDB 执行一遍,确保正确后再到生产环境的 MySQL 执行。
TiDB 热点数据优化实践经验
TiDB 根据表主键 ID 做 range 分区,将数据拆分到各个不同的 region 内。当某个 region 的数据量达到最大 size 限制后,将会进行分裂。感性来看,一旦某个 region 分裂成两个 region 后,读写压力也会拆分到两个不同的 region。但是,假设一种场景,当我们不断对一张表进行 insert 操作,而且这张表是自增主键。那么,应用插入的数据永远会落在该表 range 范围最大的 region,永远处于“添油战术”的状态,最大 range 范围的 region 所在的 TiKV 实例一直处于高负载,整个 TiKV 集群的压力无法均摊下去,出现瓶颈。
这类场景在跑批应用中比较常见。我们的优化实践建议如下:
-
确保表主键是整形类型。
-
确保表主键离散随机生成,而非自增。
通过以上两种机制能确保批量 insert 操作的写压力随机分摊到各个 region 中去,提升整个集群的吞吐量。
关于 Cloud TiDB 技术方向引子
坊间传言我们是国内第一家将所有 TiDB 都运行在 Kubernetes 容器云上的(金融)企业。我们地处西南,平日疏于与业界优秀数据库同行交流心得,是否第一不得而知,但我们的 TiDB 确实都运行在 Kubernetes 容器云上。
将 TiDB 全部运行到容器云上主要是为了提升软件部署密度,充分利用服务器硬件资源,为日后大规模部署 TiDB 集群打下基础。
根据我们的实践经验,基于物理服务器部署 TiDB 集群,至少 6 台物理服务器( pd-server 与 tidb-server 混合部署)起才能部署好一套生产环境 ready 的集群。
当我们将 TiDB 全部迁移到容器云平台后,最小 TiDB 集群资源从 6 台服务器降低成了 2 pods tidb-server、3 pods pd-server、3 pods tikv-server,硬件成本降低为原来的 30% 左右。
马上金融 TiDB 项目未来展望
到目前为止,我们对 TiDB 技术的储备已经持续了近 2 年时间。我们积累了账务归档、总账跑批等大数据量、高并发量的 TiDB 实践经验。我们还将所有 TiDB 运行到了 Kubernetes 容器云平台之上,使数据库真正获得了 Cloud-native 能力。
未来,我们将探索更多适用于 TiDB 的核心业务场景,提升 TiDB 在公司内基础技术栈的覆盖面,尤其对 TiDB 即将正式推出的 True HATP 功能充满了期待。我们将继续深度使用 TiDB,使其为消费金融行业赋能增效增效,共同创造更深远的社会价值。
目前尚无回复