前情提要
上一篇在这里: 笔记软件最重要的功能是搜索——关于笔记工具的思考
这篇的主题
上篇是这篇的理论基础,有点长篇大论。这篇则是以图为主,用真实而具体的例子,讲清楚「局部多标签」的笔记方法。
所举的例子,来自于我最近在 logseq 中所记的笔记,从中选取了一部分,以「日程笔记流水」的形式展示在这里,以产生一种笔记不断生长的效果。这里所说的生长,主要指附加在笔记上的「标签系统的生长」。
例子的主旨,是关于将心脏支架的价格从 1.3 万元降到 700 元的「心脏支架集中采购政策」。
后文有很多图,这里先放一张看下效果。
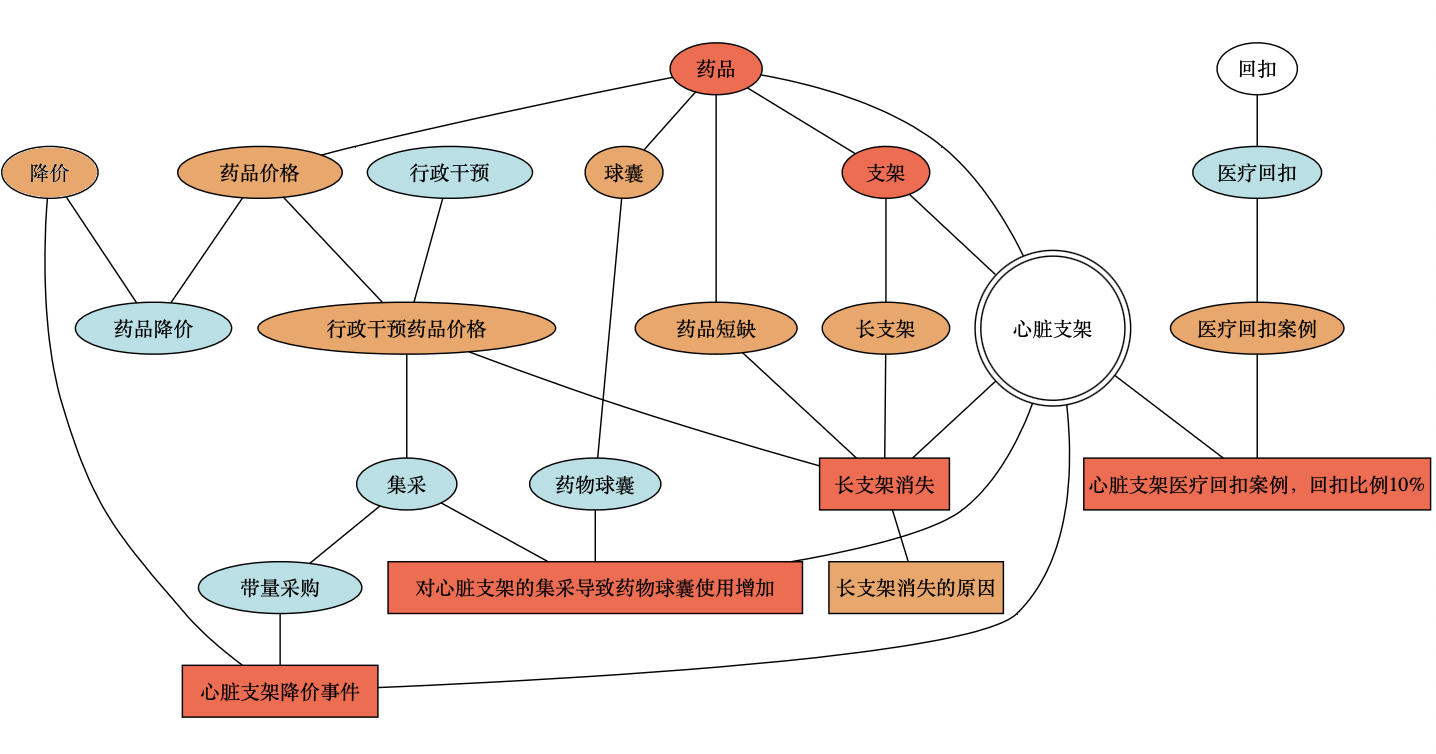
笔记的生长过程
第 1 天的笔记
- 笔记内容

- 笔记包含的「标签」
心脏支架->心脏支架降价事件;
降价->心脏支架降价事件;
带量采购->心脏支架降价事件;
- 加入「标签」后,生成的图谱
第 2 天的笔记
- 笔记

- 标签
医疗回扣->医疗回扣案例;
医疗回扣案例->"心脏支架医疗回扣案例,回扣比例 10%";
心脏支架->"心脏支架医疗回扣案例,回扣比例 10%";
- 图谱
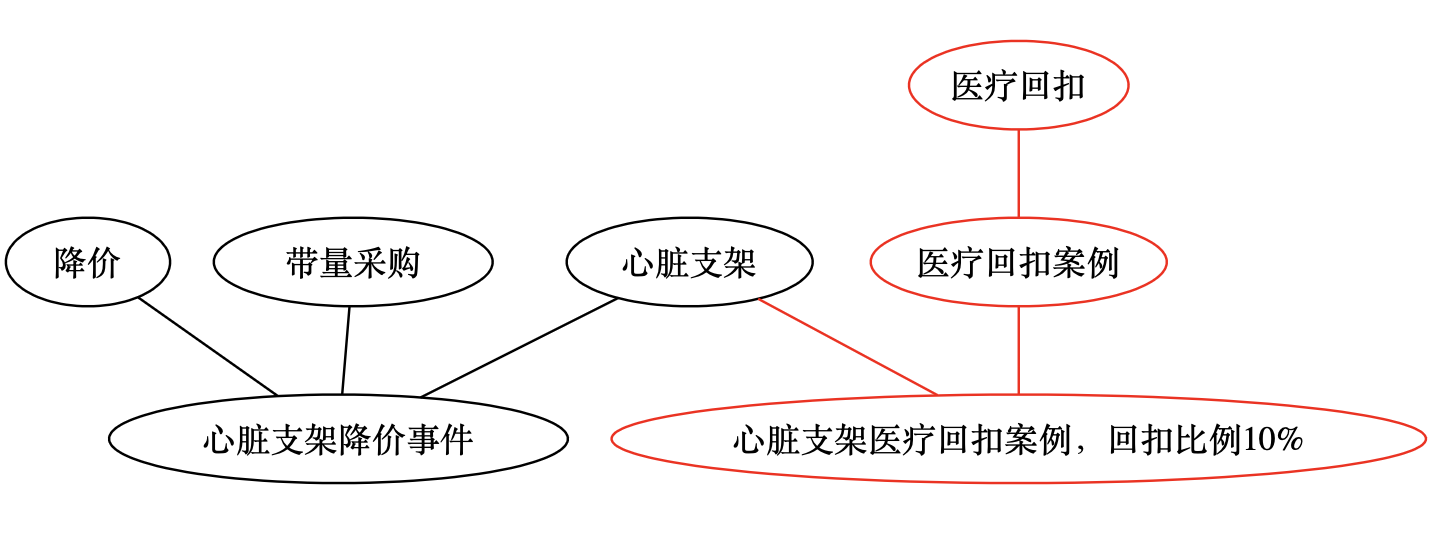
第 3 天的笔记
- 笔记

- 标签
行政干预药品价格->长支架消失;
药品短缺->长支架消失;
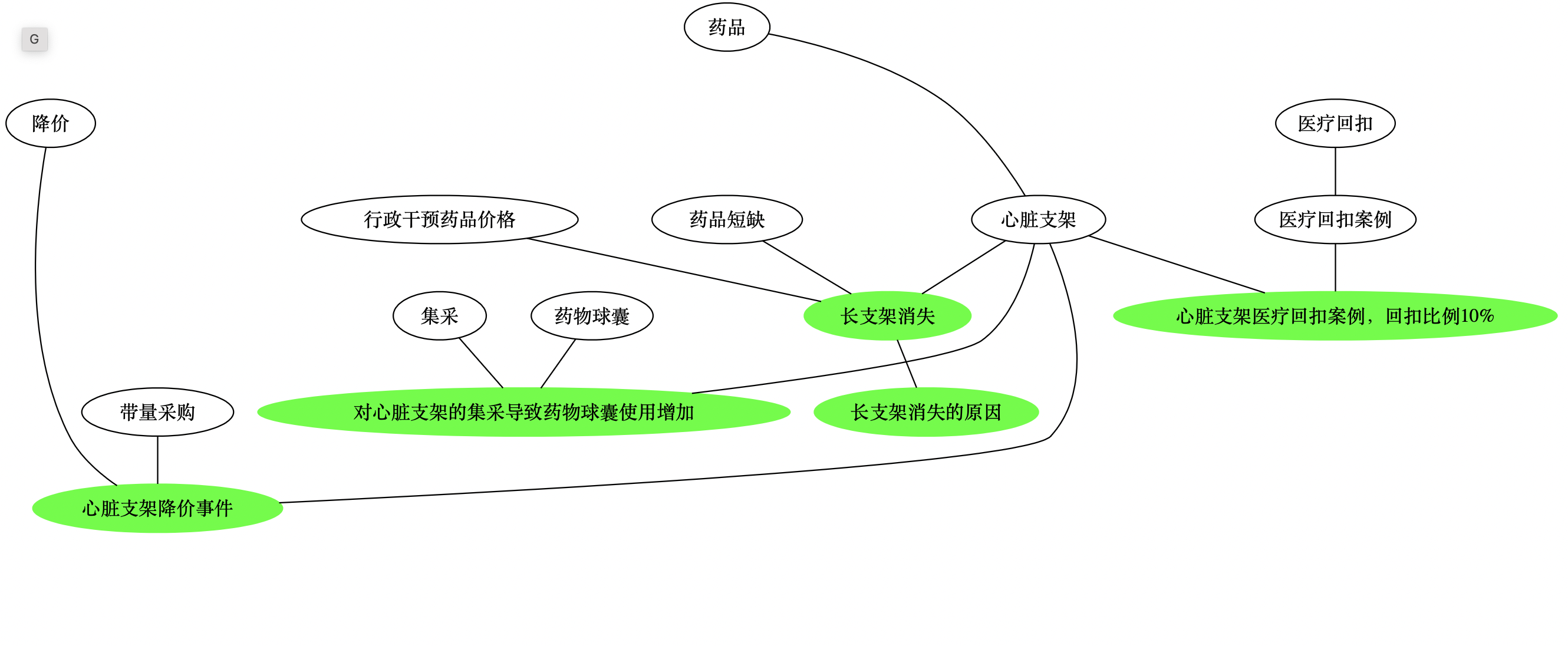
药品->心脏支架->长支架消失->长支架消失的原因;
- 图谱
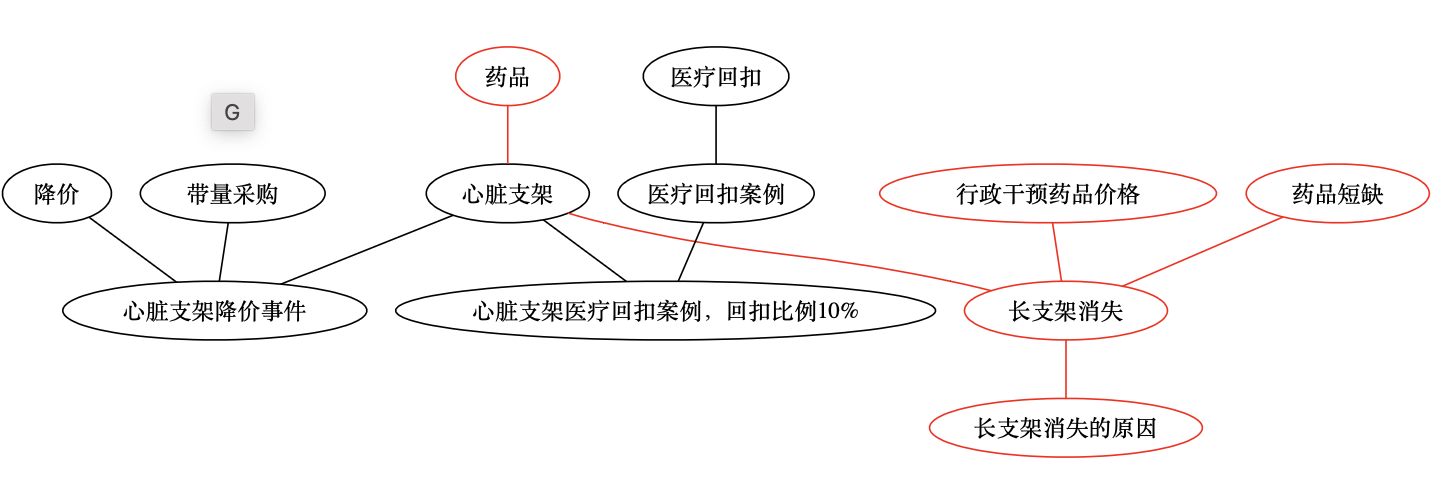
第 4 天的笔记
- 笔记

- 标签
药物球囊->对心脏支架的集采导致药物球囊使用增加;
心脏支架->对心脏支架的集采导致药物球囊使用增加;
集采->对心脏支架的集采导致药物球囊使用增加;
- 图谱
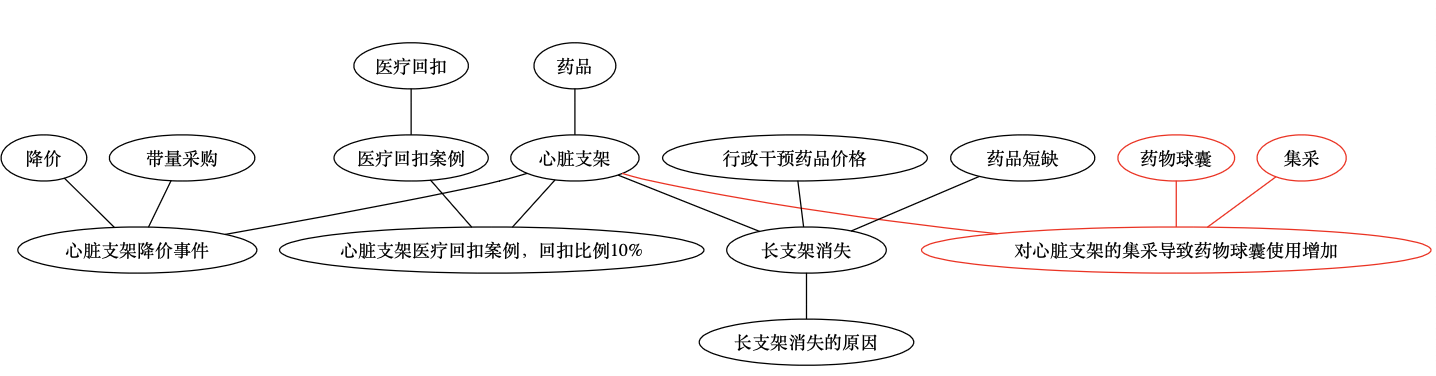
第 N 天的笔记
- ……
- ……
- ……
整理笔记中的标签关联
- 上例中,还有很多标签之间可以建立关联,例如
支架->心脏支架;
药品->支架;
药品->药品短缺;
支架->长支架->长支架消失;
集采->带量采购;
药品->药品价格->行政干预药品价格->集采;
行政干预->行政干预药品价格;
回扣->医疗回扣;
药品->球囊->药物球囊;
降价->药品降价;
药品价格->药品降价;
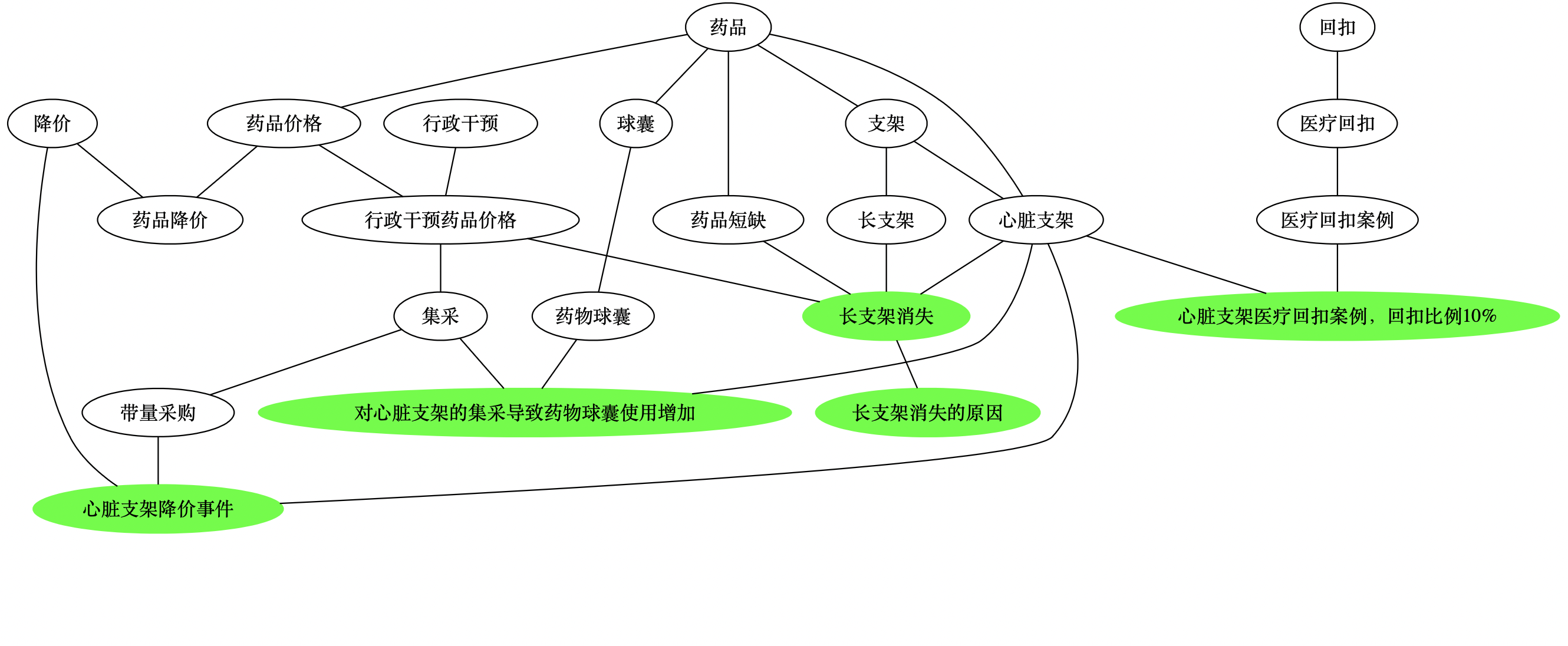
- 添加新建关联后的新图谱(红色为新添加的标签、关联关系;绿色的后文有说明)
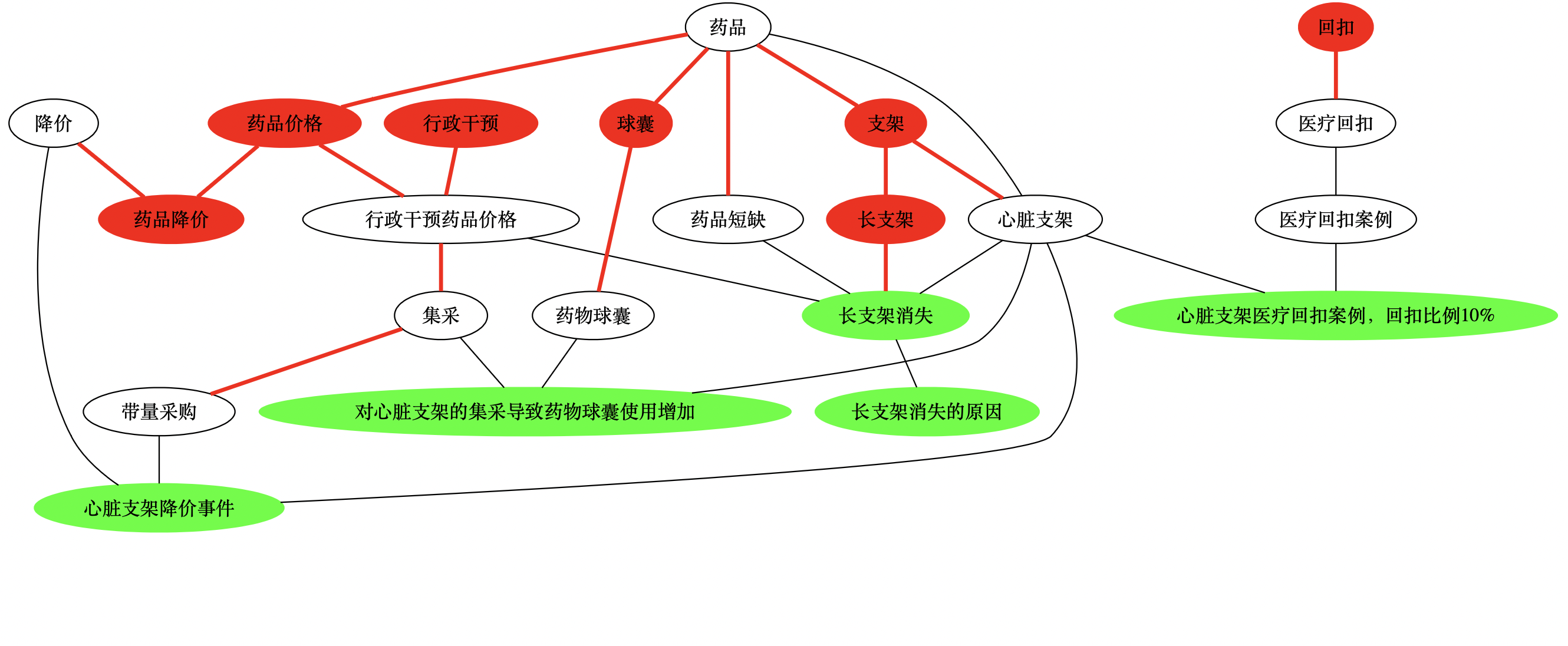
- 对比添加这些关联之前的图谱
- 最终的图谱(其中绿色的标签节点,可以理解为是一些完整的「语句」,而不仅仅是一个词)
基于标签结构的搜索
好了,标签关联起来了,标签结构已经有了,但有什么用呢?可以基于这种标签结构,优化搜索功能!搜索很重要, 这在上篇( /t/818822 )中已经提到。后面会看到,logseq 等软件提供很多重要功能,实质就是搜索。
一种搜索效果的示意图
给定某个搜索关键词,下面的例子展示了搜索的结果:标签与关键词的关联关系越近,标签颜色越暖;反之亦然。例 如红色标签与关键词关系最近,淡蓝色的最远。
- 搜索「心脏支架」
- 搜索「药品」
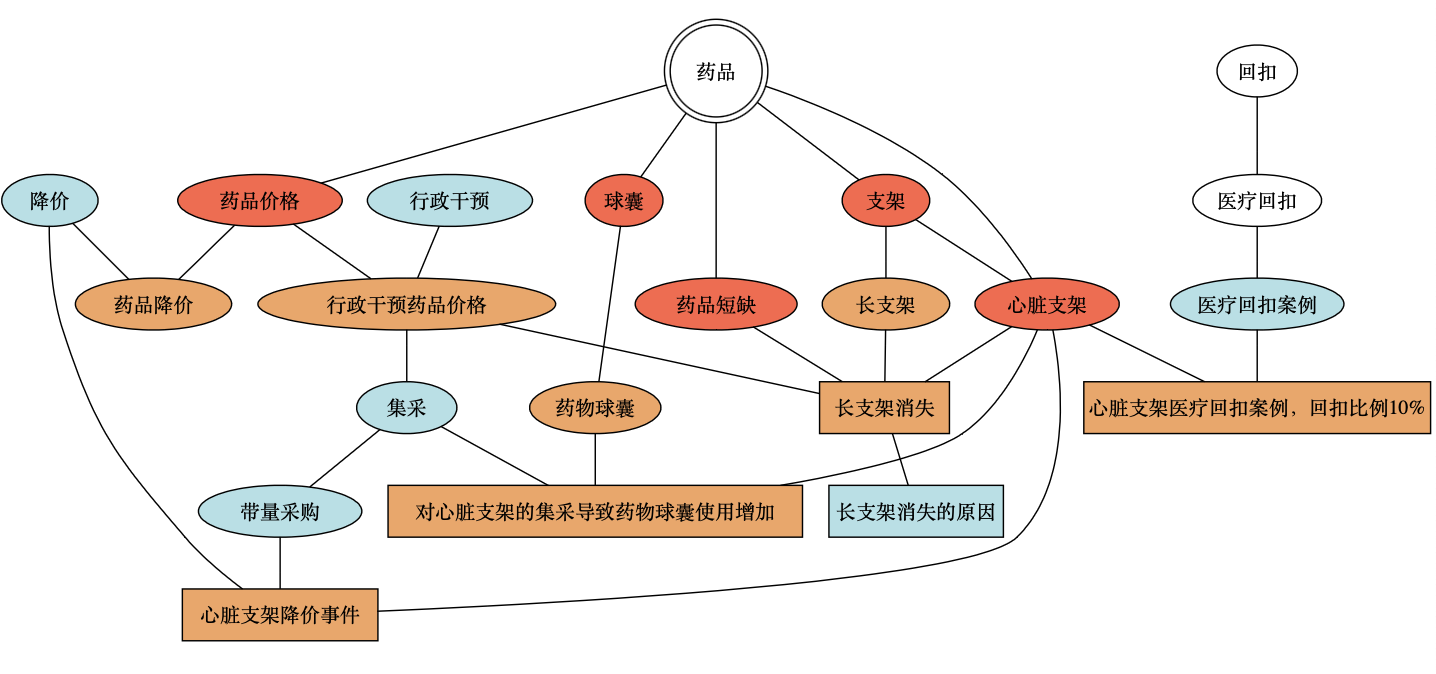
对于搜索结果的这种展示方式,只是一个我想到的示例。应该有很多方法可以比它更加简洁。比如对于标签与被搜索标签的关系远近,可以使用多层同心圆的布局来表达,或者可以使用节点与字体的大小来表达等等。
但重要的是,这种展示方式,不仅可以「表达各标签与被搜索标签的关系远近」,而且可以「利用有层次的标签结构,并在不破坏这个结构的基础上,展示搜索结果」。那么这个「有层次的标签结构」到底代表什么?又为什么要充分利用呢?
充分利用标签的结构来搜索
观察上述的标签结构,它是有结构层次的。这种层次体现在,上层的标签要比下层的更精炼:要么上层标签是下层标签的抽象,要么上层标签是下层标签的子元素。比如,
- 药品-球囊,「药品」是「球囊」的抽象
- 药品-支架
- 药品-药品价格,「药品」是「药品价格」的子元素
- 长支架消失-长支架消失的原因
所以从集合论角度看的话,上层标签代表的集合要比下层的大。这种上层涵盖下层的标签结构,可以在搜索时提供巨大的便利。
- 模糊搜索。比如,搜索时只记得某个词的一部分,例如「支架」,那么搜这个标签的话,标签结构会给到你提示线索如「长支架」、「心脏支架」等等,甚至可以间接联想到「球囊」。
- 抽象搜索。比如,多标签组合搜索的话,使用上层的抽象标签,会简化搜索过程。例如搜索「球囊 /长支架 /心脏支架 /药物支架」+「价格」的组合,可以换成搜索「心脏介入器械」+「价格」的组合。因为「心脏介入器械」标签是对「球囊 /长支架 /心脏支架 /药物支架」所有这些标签的抽象。
标签结构的进化
从「笔记生长的过程」一节可以知道,标签的结构是随着记笔记的过程不断生长的,不仅标签的规模越来越大,并且标签的结构也应该在不断完善。这里的「完善」,包含下面几点,
- 同义词合并
- 近义词抽象
- 标签充分关联
- 标签充分拆解
- 标签充分抽象
- 针对块(局部信息)的标签越来越丰富、准确。
而如果标签结构本身具有结构的话,会反过来让标签结构的改进更容易。因为你可以利用这种结构,更快速找到诸如同义词、近义词、未关联的标签、未抽象的标签、未拆解的标签,等等。反之想象一下,如果所有的标签以平铺或列表的组织形式,你又怎么去改进这些标签呢?
具有结构的标签系统,为自我改进提供很大便利。那么改进所需的时间和精力成本,就可以分散在记笔记的过程中:当添加了新的标签,或建立了新的关联后,或搜索某个标签后,发现了标签结构中的某些地方需要改进,顺手就改掉了。不需要专门抽时间特意为之。而已经改善过的那些标签,大概率是可以稳定地沉淀下来,而只需对新进来的标签作调整。
与目前 logseq 的功能对照着看
上述的多层次的标签结构,以及建立在其上的搜索功能,在目前的双向链接笔记软件中,实现的程度最大,但也并不是完全实现了(毕竟只是我的一个构思)。这里以 logseq 软件为例,看看有哪些部分已经实现,还有哪些部分未支持。
logseq 支持块,天然支持局部多标签。
每个块都可以打多个标签。这些标签可以关联起来。参考上面「笔记的生长过程」中,标签是可以打在块上的。
不过在 logseq 中,打在同一块上的多个标签,并不是通过块本身关联起来的,二是通过笔记的标题关联起来的。这样,就无法实现本文中所述的标签结构。
logseq 支持对标签搜索。有点像上述基于标签的搜索。
如下图,以列表形式显示匹配关键字的标签。优先显示匹配的标签结果,然后才是匹配的 block 和全文。

不过,这种搜索是以列表的形式,并且精确匹配关键字,也没有利用标签本身的结构。
logseq 的图谱。不利于标签结构发挥应有的作用,有很多改进空间。
- 单个页面的图谱。很有限。
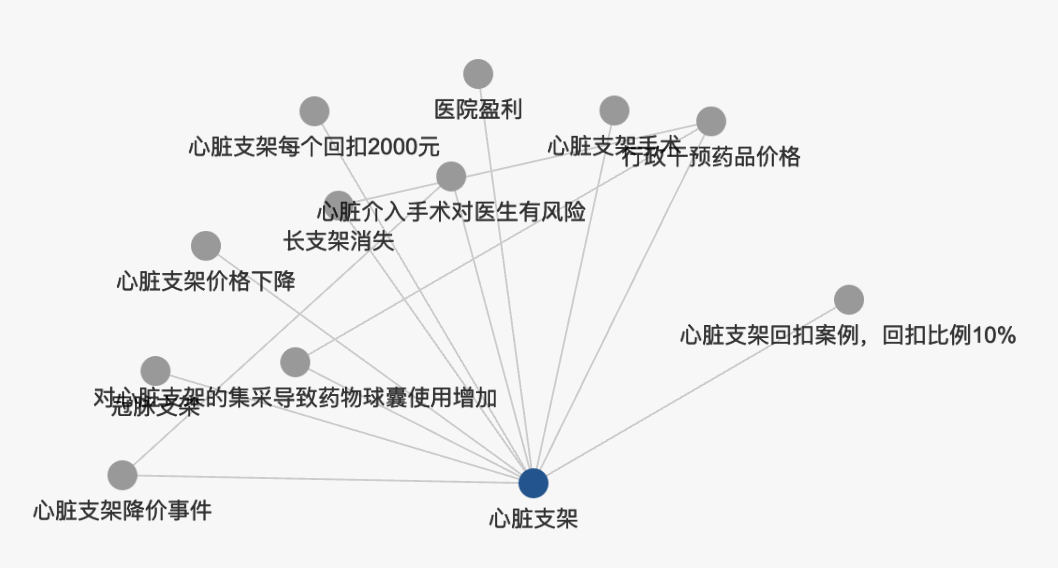
- 全局的图谱。很乱。
- 匹配某个关键词的图谱。太死板。
(图略)。图谱中只显示包含该关键词的节点。
总的来说,logseq 没有体现出标签的结构。
logseq 建立标签之间的关联的方法。可以在页面内打标签,方便程度还可以。

比如上图,在「长支架消失」页面中,打上「心脏支架」的标签,可以把 2 者关联起来。
logseq 的标签筛选功能。
例如在「心脏支架」这个页面下,可以用来筛选的反向链接(标签)有:

可以筛选「与某个 tag 关联的其他 tag 」,在我看来,这相当于「多标签搜索」功能。
总结
标签结构很重要
-
多级标签,就像地图的多级定位一样,可以很灵活地调整搜索范围,并且建立一个搜索-反馈-搜索的循环过程: 搜索标签->初步的标签结果->结合初步结果+标签结构->再次筛选增删标签->更近一步的搜索结果->再次筛选标签->...->最终的搜索结果。
-
这里的标签,并不是普通意义上的单个词或者词组,它甚至可以是一句话,例如本篇中的「对心脏支架的集采导致药物球囊使用增加」,它是对一段话的抽象概括。定位到这句话,就定位到了这段话。
-
形容多级标签结构,最合适的词是「提纲挈领」、「纲举目张」、「以点带线、以线带面」。
-
标签结构可以支持它自己的进化
并不是只有多级标签,更重要的是网状的关联
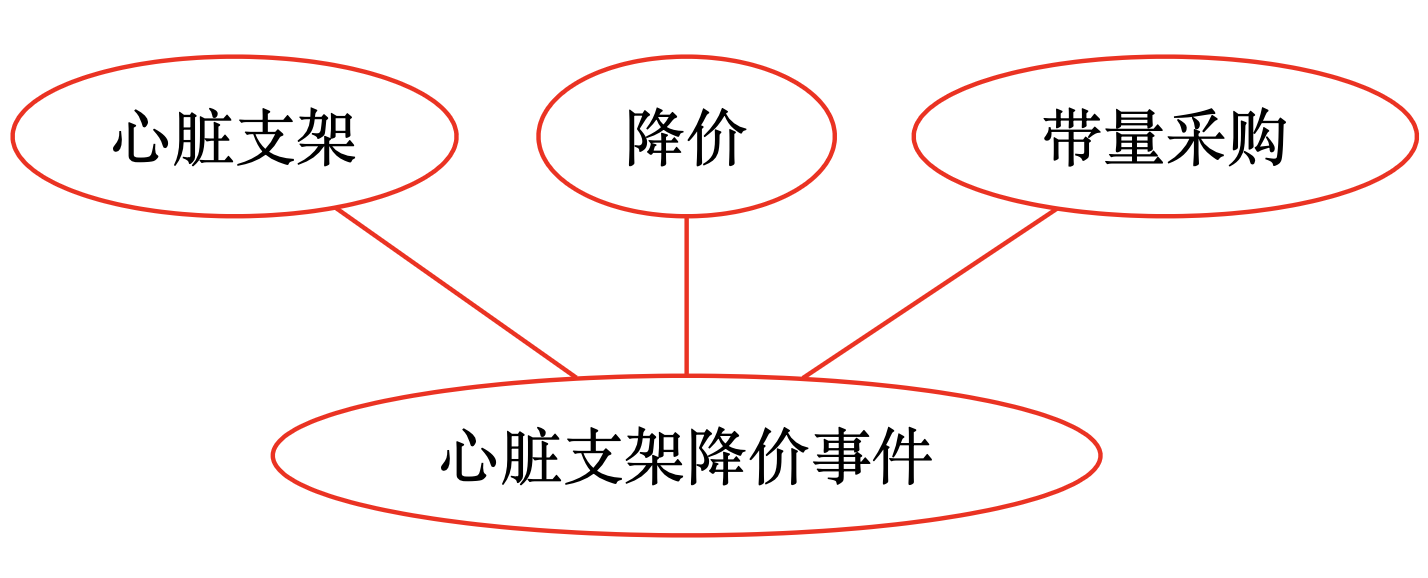
观察上面「笔记生长过程」中所给出的例子,如下图,
可以看到,「心脏支架」、「降价」、「带量采购」这 3 个标签,应该可以通过「心脏支架降价事件」这个段落,关联在一起。
目前的双链软件与这种标签系统还有些距离
以 logseq 为例,笔记的「标题」被赋予了太高的重要性。在我看来笔记标题不应该特殊化。
-
比如 logseq 中,所有块中的标签,都会与笔记的标题建立关联。这明显是不合适的。某个块的标签不一定与笔记标题有关联,是否关联要看关系强弱,强行关联只会使原本很弱的联系变得很强,导致标签结构失真。
-
标题就一定得成为标签吗?如果是的话,它在标签结构中,处于哪一层呢?
以 logseq 为例,关系图谱(也即本篇所指的标签结构),没有被很好地发掘利用。
- 某个标签的反向链接列表,本质上是对这个标签先搜索再列表展示。
- 在反向链接页中,对标签再次进行筛选,本质上是一种多标签的搜索,这个过程不需要人工介入。
- 在搜索栏中,键入关键字,先展示命中的标签再展示命中的全文,本质上也是对标签的搜索。
- 而关系图谱恰恰是搜索功能的大辅助。所以为何不把这些搜索功能与关系图谱结合起来呢,而仅仅是摆一个样子呢?
- 当然,这里讨论的只是搜索相关。除开本质上是搜索的反向链接,双链软件的块状结构有很多好的特性,比如展示很方便,引用很方便。
这篇文章,介绍了使用局部多标签形成分层的标签结构,怎样利用这种标签结构。但关于标签还有很多问题:
- 标签之间的关联关系,都是同质的吗?比如 “药品-球囊”、“药品-药品价格” 这两种关联,是一个性质吗?
- 这些性质的差异,会怎样影响搜索呢?是否能通过建立不同的关联关系,优化搜索呢?
- 对于大纲式的笔记,在上下层级的块上分别打的标签,它们之间是否应该建立关联呢?
这些留到下篇再谈吧。我自己也还有很多疑问。
欢迎大家讨论质疑。