
这是一个创建于 352 天前的主题,其中的信息可能已经有所发展或是发生改变。
今天看了个漫画网站,有几张图想存下来,发现 img 的 src 是 blob:https://www.xxxx.com/aaaa 这样的格式,直接在浏览器还打不开,network 看下
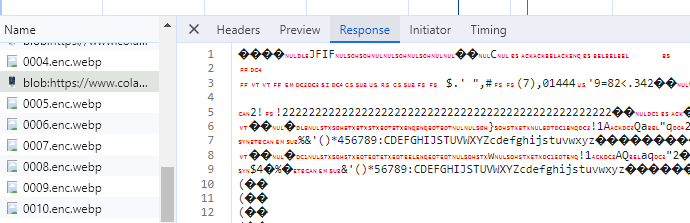
copy response 然后删除这部分 data:text/plain;base64, 成功转为图片了

我想知道的是,怎么用代码实现这一过程?怎么批量爬呢?这个 blob 好像反爬很猛的样子,不太懂啊
 |
1
Rache1 352 天前
其实就是通过 xhr 、fetch 、ws 等方式从接口拿到图片的数据。
然后在前端使用 URL.createObjectURL 创建了 blob url ,交给 Image ,然后待 onload 后,再用 URL.revokeObjectURL 销毁了资源,所以当你单独打开的时候,就资源不存在了。 |
 |
2
jifengg 352 天前
做爬虫,你都不用到这一步,这一步是因为,后端给的图片不能直接渲染(一般是加密了),需要前端获取到二进制内容后解密进行渲染,前端渲染内存里的二进制图片,就是用一楼说的这个方式。
而你做爬虫,只要找到它如何从后端获取数据(并解密)的地方就可以把数据存成文件了。 |
 |
3
chairuosen 352 天前
如果是一楼的原因,试试在页面一开始全局覆盖一个 URL 对象,透传原始 URL.createObjectURL 方法,然后实现一个空的 revokeObjectURL 方法
|
 |
4
krapnik 352 天前
直接劫持 Blob 下载这个内容就可以啦
``` let nativeBlob = Blob; // 创建一个新的构造函数,继承自 Blob function CustomBlob(blobParts, options) { // 使用 Blob 构造函数创建新的 Blob 实例 var blob = new nativeBlob(blobParts, options); // 将新创建的 Blob 实例的原型设置为 CustomBlob.prototype Object.setPrototypeOf(blob, CustomBlob.prototype); downloadBlob(blob,"1.json"); return blob; } // 设置 CustomBlob 的原型,继承自 Blob.prototype CustomBlob.prototype = Object.create(nativeBlob.prototype); CustomBlob.prototype.constructor = CustomBlob; Blob = CustomBlob; function downloadBlob(blob, fileName) { // 创建一个下载链接 var url = URL.createObjectURL(blob); // 创建一个隐藏的<a>标签 var a = document.createElement('a'); a.style.display = 'none'; document.body.appendChild(a); // 设置下载链接和文件名 a.href = url; a.download = fileName; // 模拟点击<a>标签来触发下载 a.click(); // 清理并移除<a>标签 document.body.removeChild(a); // 释放创建的下载链接 URL.revokeObjectURL(url); } const obj = { hello: "world" }; const blob = new Blob([JSON.stringify(obj, null, 2)], { type: "application/json", }); ``` |
 |
5
Mikawa 352 天前
用 Blob 后,图片的内容是从接口拿的,估计是为了防盗链+可能实现类似瓦片地图的功能
你希望大量爬取,还是在访问的时候去拿,如果是在访问的时候拿,可以用油猴脚本之类的方式简单做下 |