
[开源] 扫描件 PDF 转 Markdown / EPUB,自动修复 OCR 错误
BlackHole1 ·PRO
这是一个创建于 213 天前的主题,其中的信息可能已经有所发展或是发生改变。
最近我们开源了一个 PDF 处理工具 - pdf-craft,专注于解决扫描书籍 PDF 转换的痛点,让书籍数字化更智能。pdf-craft 支持将 PDF 转为 Markdown 和 EPUB ,智能处理文本、图表、公式等内容,适用于技术文档、书籍数字化、论文研究等场景。
痛点与解决方案
- PDF 不便于移动设备阅读:将 PDF 转为 EPUB ,适配各种屏幕大小
- 书籍结构混乱:智能分析章节、目录,重建结构化内容
- 注释和引用难以追踪:使用 LLM 智能处理注释和引用
- OCR 识别错误多:结合 LLM 自动矫正识别错误
- 扫描件 PDF 难以被 AI 、代码处理:分析并结构化 PDF 扫描件,以供 AI 、代码读取
主要特性
-
PDF 转 Markdown
- 纯本地运行,GPU 加速支持
- 智能过滤页眉页脚等无关元素
- 自动处理跨页文本顺接
- 图表、公式自动提取为图片
-
PDF 转 EPUB
- 智能构建书籍结构和目录
- 提取并保留注释和引用,并在 EPUB 中以合适的方式重新组织
- 支持中断恢复分析
- LLM 辅助校正 OCR 错误
-
技术亮点
- 结合 DocLayout-YOLO 布局分析
- 使用 OnnxOCR 进行文本识别
- 集成 layoutreader 优化阅读顺序
- 可接入 DeepSeek 等 LLM 服务
技术细节
项目基于 Python 开发,可通过 pip 安装:
pip install pdf-craft
核心使用方法示例:
# PDF 转 Markdown (纯本地处理)
from pdf_craft import PDFPageExtractor, MarkDownWriter
extractor = PDFPageExtractor(
device="cuda:0", # GPU 加速
model_dir_path="/path/to/model/dir/path",
)
with MarkDownWriter(markdown_path, "images", "utf-8") as md:
for block in extractor.extract(pdf="/path/to/pdf/file"):
md.write(block)
对于更复杂的 EPUB 转换,可以接入 LLM:
from pdf_craft import LLM, analyse, generate_epub_file
# 配置 LLM
llm = LLM(
key="sk-XXXXX",
base_url="https://api.deepseek.com",
model="deepseek-chat",
token_encoding="o200k_base",
)
# 分析 PDF
analyse(
llm=llm,
pdf_page_extractor=extractor,
pdf_path="/path/to/pdf/file",
analysing_dir_path="/path/to/temp",
output_dir_path="/path/to/output",
)
# 生成 EPUB
generate_epub_file(
from_dir_path="/path/to/output",
epub_file_path="/path/to/book.epub",
)
实际效果


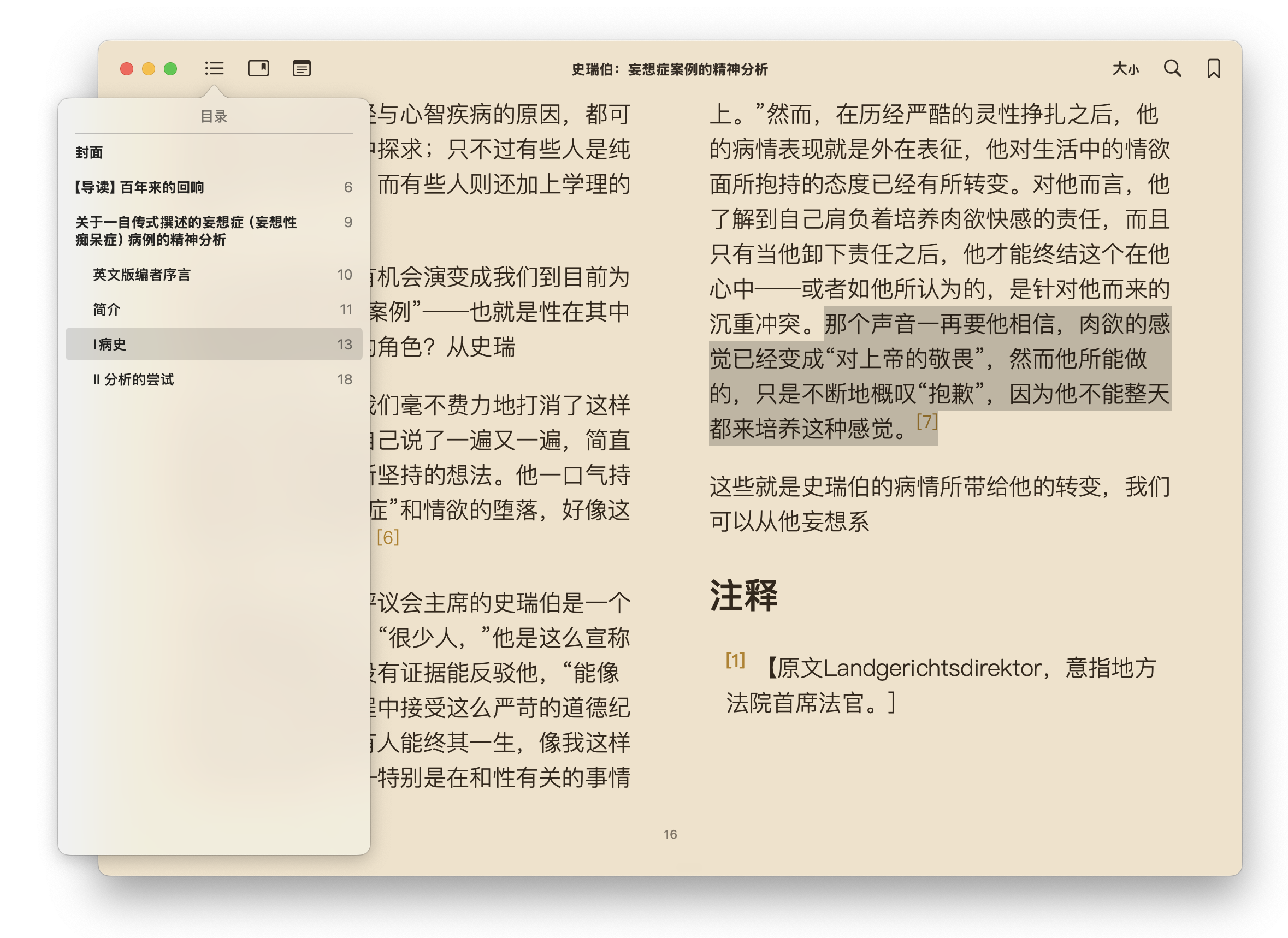
立即体验,无需环境配置
想快速尝试 pdf-craft 而不想折腾环境配置?我们提供了更简单的方式: 使用 OOMOL Studio 一键体验:pdf-craft for OOMOL studio
OOMOL Studio 是我们开发的工作流 IDE ,内置了隔离的运行环境,无需复杂配置,即可立即体验 pdf-craft 的全部功能。 关于 OOMOL Studio 可以查看之前的介绍: 一款全新的工作流 IDE。
当然,pdf-craft 仍然完全开源,你依然可以按照上述方法在自己的环境中配置使用。
适用场景
- 技术文档阅读:将繁杂的技术文档转为结构化内容
- 书籍数字化:把纸质扫描书转为便携的电子书
- 论文研究:快速提取论文内容并方便引用
- 学习材料整理:将课程讲义处理为易于学习的格式
- 代码文档提取:从 PDF 教程中提取可用代码
开源与社区
项目刚刚起步,我们非常欢迎各位 V 友参与:
- GitHub 地址:https://github.com/oomol-lab/pdf-craft
- 问题反馈:https://github.com/oomol-lab/pdf-craft/issues
- 演示视频:Bilibili 链接
如果觉得不错,欢迎给项目点个 star ⭐,有什么想法也可以在评论区交流,或者提交 PR 一起完善这个工具。
你也可以通过 https://oomol.com/community/ 找到我们。
 |
1
simple233 213 天前
牛的,那么快又有新东西了
|
 |
2
uCharles 213 天前
好厉害
|
 |
3
chjian 213 天前
大佬厉害
|
 |
4
regent 213 天前
对于爱看书的人是一个福音,谢谢!
|
 |
5
jimrok 213 天前
感觉现在正处在寒武纪大爆发阶段,各种新应用层出不穷。
|
 |
6
kitty7030 213 天前
可以增加个功能 再转化为 pdf
|
 |
8
b821025551b 213 天前
@moskize pdf 的兼容性更好,随便拖到浏览器就能看;这个过程就是将扫描版 pdf 转成矢量版 pdf ,提升清晰度,缩小文件体积。
|
 |
9
timeisweapon 213 天前
对于普通个人用户来说,还是在线转换工具方便
|
 |
10
yibie 213 天前
能接 Ollama 吗?
|
 |
11
yazoox 213 天前 via Android
这个是真的牛逼!
|
 |
12
docx 213 天前 via iPhone
分栏的 PDF 能完美解析吗
|

 |
15
sunnysab 212 天前
flowhub 中点击 Open By OMMOL Studio 没有反应(似乎只是刷新了当前页面)。
分析了《聪明在于勤奋,天才在于积累》(华罗庚)一书,第 4 页的分数( 22/7 )没有识别成公式,整本书识别得不错,比当时导入微信读书时识别得强。 |
 |
16
jhytxy 212 天前 via iPhone
求 docker 镜像
|
 |
17
urlk 212 天前
微软貌似也有个 markitdown 专门转 PDF 的, 貌似没有 orc
|
 |
18
ayang23 212 天前
效果貌似不错
|
 |
19
EngAPI 212 天前
不错啊,造福墨水屏
|
 |
20
bfdh 212 天前
model_dir_path="/path/to/model/dir/path",
新手求问,这个应该从哪里下? |
 |
24
zero469 212 天前
非常好的 idea ,太牛逼了
|
|
25
zero469 212 天前
不知道作者有没有尝试过 7B 或 32B 的 LLM ,如果效果也 OK 的话连带模型做一个纯本地的方案感觉更有吸引力
|
 |
26
Dreamerwwr 212 天前
在哪里配置 LLM 的 API 呢?打开后,没看到配置的位置
|
 |
27
KiriGiri 212 天前
厉害,做了我想做的。
|
 |
28
ration 212 天前
喜欢在电纸书上看书,这个真不错,谢谢
|
 |
29
cyp0633 212 天前 好用,不过现在 LLM 主要是用来纠正文字吧,我觉得可以用 Gemini 等多模态 LLM 一块儿识别公式,转换成 LaTeX 格式
|
 |
31
hinate 212 天前 via Android
太强了👍🏻
|
 |
32
cooper 212 天前
这个好,已 star !
|
 |
33
manning 212 天前
mathpix 上付费的 PDF 转 markdown ,这个能代替吗
|
 |
34
3085570450tt 212 天前
跟 PyMuPDF 比起来怎么样呢?同时 PyMuPDF 也有 LLM 的支持 https://pymupdf.readthedocs.io/en/latest/pymupdf4llm/
|
 |
35
moskize 212 天前
@3085570450tt 看介绍它们好像是为 LLM 提取文本,而不是用 LLM 处理文本。而且 PyMuPDF 我记得是不提供 OCR 的。
|
 |
37
Yien 212 天前 via Android
厉害(òωó)👍
|
 |
38
luyg 212 天前
厉害,我要试试
|
 |
39
akira 212 天前
先给个 star 后面有空了 试一下
|
 |
40
oyjt 212 天前
大佬,厉害呀。先 star 了为敬
|
 |
41
yueyueniao89 212 天前
先马克,pdf 转 epub
|
 |
42
x4gz 211 天前
这个带多线程吗 不然有的几百页的书转起来也太慢了
|
 |
44
PersueYan 209 天前
这个有点意思
其他格式文档统一转 pdf 好搞 然后 pdf 统一提取文字图片,再分类按需处理 先 mark 了 就是不知道复杂格式的 pdf 识别和提取准确度怎么样 |
 |
45
zizek 207 天前
初步用了一下 pdf-craft 的本地模型功能,发现它是把矢量 pdf 文档当成图片,重新 OCR 之后形成的文本。
请教一下,有这样一个需求,能用 pdf-craft 实现吗? 完全是矢量化的 pdf 文档,已经不需要识别了。只需要内容提取出来,生成 epub 。 其实现在 calibre 能够完成这样的转化,但缺点是,跨页的段落不能合并成一段,这样一句话就会被放在两个段落里。pdf-craft 似乎能够很好地合并段落,保持句子的完整性。 如果提供“直接处理矢量 pdf"的选项,那就能节省很多时间。不知是否可能? |
|
46
moskize 206 天前
@zizek 没错,现在会多此一举做这个动作。这里是一个优化点,等于要允许跳过 OCR 截断直接进入分析阶段。calibre 估计没有做合并段落操作。这个用算法很难准确识别,毕竟 PDF 本身是没有这个信息的。pdf-craft 完全是让 LLM 来判断句子到底有没有被切断,然后拼起来。
|
 |
47
isSamle 185 天前
能不能整个 docker😂
|