
这是一个创建于 2970 天前的主题,其中的信息可能已经有所发展或是发生改变。
比如《字符编码笔记: ASCII , Unicode 和 UTF-8 》 是阮老师 10 年前写的一篇关于字符编码的科普文章,现在用 Google 搜关键字该文章依然名列前茅,可见他的文章有多大影响力,但里面的内容是否正确是值得商榷的事。
中文维基百科对 Unicode 的解释也是让人一头雾水,摸不着头脑。看看阮老师怎么说:
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode ,就像它的名字都表示的,这是一种所有符号的编码。
这句话读起来很拗口,有三个地方出现了「编码」二字。不知阮老师对「编码」的理解是什么?但可以肯定的是这三个「编码」在这句话里面不是同一个意思。
「编码」作动词使用时就是把一个字符(严格一点说是字符在字符集中的编号 code point )转换成一个字节序列,以便在网络传输或者存储到文本中。比如「好」在 Unicode 中的编号是 U+597d ,经过 UTF-8 编码后会转换成二进制序列是 '\xe5\xa5\xbd' 。作为名词使用时,就是指一种具体的编码实现方式,比如 ASCII 编码, GBK 编码, UTF-8 编码
其实 Unicode 是一个囊括了世界上所有字符的字符集,其中每一个字符都对应有唯一的编码值( code point ),然而它并不是一种什么编码格式,仅仅是字符集而已。 Unicode 字符要存储要传输怎么办,它不管,可以用 UTF-8 、 UTF-16 。
再来看阮老师说 Unicode 的第二个问题:
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0 ,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
Unicode 并没有统一规定每个符号用三个或者四个字节表示。 Unicode 只规定了每个字符对应到唯一的代码值( code point ),代码值 从 0000 ~ 10FFFF 共 1114112 个值 ,真正存储的时候需要多少个字节是由具体的编码格式决定的。比如:字符 「 A 」用 UTF-8 的格式编码来存储就只占用 1 个字节,用 UTF-16 就占用 2 个字节,而用 UTF-32 存储就占用 4 个字节。
再看来看这张图:

阮老师对 Unicode 编码的解释是:
Unicode 编码指的是 UCS-2 编码方式,即直接用两个字节存入字符的 Unicode 码。这个选项用的 little endian 格式。
UCS-2 是什么鬼, UCS-2 是使用两个定长的字节来表示一个字符,而 UTF-16 是使用两个变长的字节,遇到两个字节没法表示时,会用 4 个字节来表示,因此 UTF-16 可以看作是在 UCS-2 的基础上扩展而来的。而 UTF-32 与 USC-4 是完全等价的。
之所以在 Windows 下有 Unicode 编码这样一种说法,其实是 Windows 的一种错误表示方法,它真正的编码类型是 UTF-16LE 编码。
他又说:
Unicode 规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"( ZERO WIDTH NO-BREAK SPACE ),用 FEFF 表示。这正好是两个字节,而且 FF 比 FE 大 1 。
如果一个文本文件的头两个字节是 FE FF ,就表示该文件采用大头方式;如果头两个字节是 FF FE ,就表示该文件采用小头方式
第 1 条附言 · 2017-02-28 09:44:40 +08:00
发现大家已经不再是讨论问题本身了,阮一峰老师的文章绝大部分还是很有有指导性的。在此给大家造成的困扰,表示抱歉。
散了吧,不值得浪费大家时间。
散了吧,不值得浪费大家时间。
 |
1
onsala 2017-02-27 21:12:12 +08:00
Linux 系列的科普文章也是
|
 |
2
watzds 2017-02-27 21:15:00 +08:00 via Android
有错误不是很正常吗,看谁的文章都要自己判断
你打算给他的所有文章做勘误? |
 |
3
FrankFang128 2017-02-27 21:15:21 +08:00
错误挺多的,不影响我看他的文章。
他原本就不是程序员啊。 |
 |
4
peneazy 2017-02-27 21:16:28 +08:00
有错误不是很正常,我自己的技术博客都很多错误
|
 |
5
onlyhot 2017-02-27 21:21:03 +08:00 via iPhone @watzds 很多人没有这个判断的水平。换句话说,如果懂这个,我还看这篇文章干什么?就是不懂才看,既然不懂,就别谈自己判断了。
|
 |
6
Kokororin 2017-02-27 21:26:18 +08:00 via iPhone
摘下眼镜,模糊的看最好
|
 |
7
notes 2017-02-27 21:27:54 +08:00 via Android
|
 |
8
HLT 2017-02-27 21:33:15 +08:00
他没有工程经验
|
 |
9
i8d0g 2017-02-27 21:41:49 +08:00
哈哈 你说这篇文章我就乐...
我当时被乱码问题折磨,然后想把这问题搞清楚,网上看了些文章,有了些概念,结果一不小心看了他这个“ Unicode 与 UTF-8 之间的转换” 被绕进去了... |
 |
10
21grams 2017-02-27 21:46:18 +08:00
吹毛求疵,谁的文章没有错?
|
 |
11
gouchaoer 2017-02-27 21:50:10 +08:00 via Android
git 不安装 gui
|
 |
12
SuperMild 2017-02-27 22:05:07 +08:00 他的博客开放评论,可自由发言指出错误,想深入了解的人自然会看评论。
|
 |
13
crab 2017-02-27 22:09:45 +08:00
FE FF 大端
FF FE 小端 这边描述哪里错呢? |
 |
14
lzjun OP @crab FEFF 作为零宽度非换行空格仅仅是它出现在字节序列的中间时的作用,用户看起来就是一个空格,不过从 Unicode3.2 开始就只能规定 FEFF 只能出现在字节流的开头,只用于标记字节序(大小端)。这是来自维基百科的说法
|
 |
17
vultr 2017-02-27 22:22:12 +08:00
与其花大量的时间去找错误,还不如自己写几篇正确的来得有意义。
|

 |
19
qingshi 2017-02-27 22:26:32 +08:00
@FrankFang128 啊,阮一峰不是在阿里做程序员吗?
|
 |
20
phrack 2017-02-27 22:37:01 +08:00 via Android
有错误正常,特别是涉及到编码的文章。
讲解编码的文章我只怕看了不下十篇,很多是越看越迷糊,有一篇讲的非常好可惜一时没找到。 |
 |
21
Yc1992 2017-02-27 22:39:02 +08:00 via Android 有必要 @谭浩强
|
 |
22
ecmadao 2017-02-27 22:41:59 +08:00 via iPhone 讲真,我觉得他的一些文章算是一种“搬运工”的水准,但我们应该辨证的看待。对于小白而言,他的文章的确显得很新,可以作为粗浅的入门,但是比较有经验的人可能就不太能看得上了。我自己从前入门的时候还会看看那些文章,但后来就觉得其实写的很浅,也只是汇总了网上资料的水平。而对于文中的错误,指出来是绝对没问题的,人非圣贤孰能无过嘛,但总有人带着戾气进行攻击,同时也有人盲目崇拜,这就真心不该了
|
 |
23
laoyuan 2017-02-27 22:45:54 +08:00
我觉得,谁要是讲编码的时候,能提到 MySQL 的 utf8 并不支持所有 UTF-8 , utf8mb4 才相当于 UTF-8 ,那么,他的水平是有的
|

|
26
FrankFang128 2017-02-27 22:49:36 +08:00
@qingshi 写了十年的博客之后,才做的程序员。
|
 |
27
ljcarsenal 2017-02-27 22:50:28 +08:00 via Android
@FrankFang128 他在阿里的 title 不是前端开发专家么
|

|
30
laoyuan 2017-02-27 23:03:45 +08:00
可能大家接触 utf8mb4 多是储存 Emoji 的需求,我是碰到不常用汉字了, 4 字节 UTF-8 的汉字,插入数据库报错,我很早就碰到了,当时 MySQL 还没出到 5.5 ,后来有一天我突然想上 V2 来问问,就有人告诉我用 utf8mb4 了
|
 |
31
kuntang 2017-02-27 23:03:46 +08:00
@ljcarsenal 授予专家的 title 更多的看重他在程序员圈子里面的影响力吧,以此收揽人才?
|
 |
32
rashawn 2017-02-27 23:11:19 +08:00 via iPhone
楼主你拿 Google 搜中文干嘛
这种文章,搜英文的完全没有废话,基本想找的东西很快就能找到,而且比中文的要新一些。 你竟然看一篇旧的文章还看这么仔细,好闲…… |
 |
33
xuboying 2017-02-27 23:11:53 +08:00 via Android 楼主你给他留言他会修改的,不要在这里揭短,承认你 unicode 这块熟练,但你未必有人家有耐心有时间持续的写程序博客。
|
 |
34
xianlin 2017-02-27 23:19:18 +08:00 软一封确实不是程序员出身,但是他也是为了分享知识才写的博客,写东西一定会有错误,有了错误就会改正,希望你的这些建议可以通过更直接的方式反映给作者,造福众生,普及程序大法,此乃一大幸事。否则浪费了这么长的一个帖子。
|
 |
35
thekll 2017-02-27 23:36:00 +08:00 via iPhone
字符集 character sets 和字符编码 character encodings 是两个不同的概念,经常被乱用。
unicode 标准包含了统一字符集、编码方式( utf-8,uft16,ucs-2/4 等)、和字符相关的数据文件,一组与字符属性相关的条目定义等。 毕竟这是最基础的概念,各种文件的编码问题都与此有关。 |
|
36
lzjun OP @xuboying 不是揭短,更没有比他熟悉。我也是为了弄懂字符编码查阅了很多资料,才发现他写的有些地方不严谨。才逐一指出,请理性看待这问题。我写这个也纯粹是希望遇到类似问题的人不要受误导,如果你不是目标用户完全可以忽略
|
 |
37
williamx 2017-02-27 23:46:01 +08:00 Unicode 这块是比较难介绍的,因为现实中,这块已经是比较混乱了——当然,计算机相关行业的名词一向都是比较混乱的。
在我的理解, Unicode 是一个标准, UTF-8 等是这个标准的实现,这个很简单,很清晰。 然后在某些不那么严格的环境下,不需要明确指出到底是哪一种编码的情况下,大家用 “ Unicode 编码”这个说法来 表示实现。这其实也是很好理解的,没有错误。 可是第一个混乱 出现了,“ Unicode ” 这个单词在实际使用中没有被单纯的认为是一个标准的名字,它还被用于其他的地方,比如阮文中的“ Unicode 只是一个符号集”,比如其他文章中出现的“ Unicode 就是上文中提到的编码字符集”,还有其他很多的说法,直接让人搞不清楚 Unicode 到底是什么,连原本没有问题的“ Unicode 编码”这个说法也 模糊起来了。 其次,某些软件商出于各种目的,比如没完全理解这些概念,比如为了对普通用户更友好,比如照抄其他软件的设定等等原因,又在他们的软件中用了“ Unicode 编码”这个东西。悲哀的是很快他们就发现了“ Unicode 编码”这个说法的局限性,不得不又引进了更具体的 UTF-8 , UTF-16 这样的设置,好像 “ Unicode 编码”和 UTF-8 是平级的,于是这就更乱了。 于此同时,某些软件又把字符编码和文件格式搞在了一起,在文件的开头加了两个字节,当然它们也有苦衷,但是这尼玛直接导致其他一些软件硬生生在文本的开头多了两个不可见字符。 再加上另一个组织的 UCS 标准,再加上后来 UCS 和 Unicode 又合并了,直接导致了不学历史的人是搞不懂这些概念的。 至于阮的这篇文章,我同意你的看法, 严格来说,确实有很多的错误——当然,严格来说,我上面写的这些也是有很多错误的——这毕竟不是论文,并不需要每个表述都去查证。 |
 |
39
quericy 2017-02-27 23:58:44 +08:00
人非完人,是否会有错误和是否有名气无关。
而且个人博客有错误在所难免,评论区的意义不也就是对问题的探讨么? UTF-8 的问题之前也踩过坑,但是不懂的话一般都会谷歌多篇资料来看吧 随便搜到一个答案就当作正解的话早就被那些刷 SEO 的垃圾采集站给坑死了 博客里的东西至少提出问题都可以对内容做出探讨和修正,比那些搬运转载的资料靠谱的多 |
 |
40
cxbig 2017-02-28 00:04:33 +08:00
挑别人的毛病很容易,问题是 10 年前的文章抓着不放有点没劲了。
每个人都在成长,很多对事物的理解是不断变化的。 同上面一些人说的,如果文章依然在,倒不如直接去留言讨论。 |
 |
41
dtfm 2017-02-28 00:18:09 +08:00
@mimzy 我是看 pymysql 的 Gihub Readme 学到的 ,当时奇怪为什么作者要设定 charset =utf8md4 这个奇怪的东西
|
 |
43
ltux 2017-02-28 00:36:52 +08:00 看这种二手知识时带有自己的思考是对的,本来别人文章里有不足之处,指出即可,别整天叫板这个叫板那个,这有什么好叫板的呢?我个人很不喜欢这种标题。
第一个问题: 楼主说“ Unicode 并不是一种什么编码格式,仅仅是字符集而已。 Unicode 字符要存储要传输怎么办,它不管,可以用 UTF-8 、 UTF-16 。” 那么我们看看 unicode 自己是怎么说的: http://www.unicode.org/standard/principles.html The Unicode Standard is the universal character encoding standard used for representation of text for computer processing. Character encoding standards define not only the identity of each character and its numeric value, or code point, but also how this value is represented in bits. The Unicode Standard and ISO/IEC 10646 support three encoding forms (UTF-8, UTF-16, UTF-32) that use a common repertoire of characters. 翻译: The Unicode Standard 是一种 universal character <加粗>encoding</加粗> standard. Character encoding standards 不止定义每个 character 的 code point ,也定义这个值如何用比特表示。 The Unicode Standard 支持三种 <加粗>encoding</加粗> forms ,即 UTF-8, UTF-16, UTF-32 看见这里是怎么使用 encoding 这个词的么?这里一点儿都不装逼也不纠结,该用 encoding 就用 encoding ,该解释 code point 就解释 code point, 一点不矛盾。另外, unicode 说自己不止定义字符的代码点,也定义该代码点的值如何用比特表示,根本不像楼主所说的什么“ Unicode 仅仅是字符集而已”。 第二个问题: 阮一峰说的是“如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0 ”,注意说的是如果,如果,如果,重要的事情说三遍。楼主不要上来就想搞个大新闻,说什么“ Unicode 并没有统一规定每个符号用三个或者四个字节表示”, unicode 当然没有这么规定,阮一峰也没说 unicode 这么规定了,阮一峰说的是如果,如果,如果,是为了引出下文的 utf-8 、 utf-16 、 utf-32 |
 |
44
intret 2017-02-28 00:38:27 +08:00
上次为了自己解析 UTF-8 数据流中的 Emoji (什么人种皮肤颜色+表情合成)上 http://www.unicode.org 看,几天几夜地看,头晕眼花。
|
 |
45
qq286735628 2017-02-28 00:48:58 +08:00
有错直接原文评论指正,相信他会接受的。
写东西主要还是写给自己看,用自己的语言陈述一遍加深印象, Google 排名高误导人这不能怪他。 写博客风格很多种,严谨仅仅是其中一种形式,正如此文你让我知道了他文章不正确的内容。 但这种背后捅刀子,以后谁还写敢博客谁还敢分享?(看了 lz 前面的评论,原来 lz 没这个意思,但原文和标题火药味还是蛮重的) 说到这顺便感慨一下,最近面试了很多童靴,讲很多知识点都讲得头头是道,但是我再问一句“这是真的吗?你验证过没有?”就都哑巴了,都不去实践验证一下,看到别人写什么就信什么。 lz 这种深究的精神赞一个。 |
 |
46
seeker 2017-02-28 02:12:43 +08:00
以前看看自己不懂的还以为是对的,结果后来看到一个我懂的,发现他就是以其昏昏使人昭昭.. 于是再也不敢看了,怕记个错误的东西,也怕耽误时间理解错误的东东。
|
 |
47
stabc 2017-02-28 02:30:36 +08:00
看正文挺赞的,看评论吓一跳。
|
 |
48
congeec 2017-02-28 06:14:21 +08:00 via iPhone
@stabc 嗯啊,楼主正文就事论事,并没有针对阮一峰。但是只看标题就感觉楼主在跟人撕逼。看楼上评论我觉得好多人根本就没读文章
|

 |
50
DeutschXP 2017-02-28 07:46:06 +08:00
@lzjun 可能我说的很不客气,但我能看到的事实,只能让我做如此推断:一个新人,试图想要踩在别人肩膀上面往上爬。大家都是明白人, IT 圈不是娱乐圈,吃相请不要那么难看。
如果你想反驳,那么很简单,请拿出你在 2017 年 2 月 27 日之前和阮一峰的沟通证据,无论是邮件还是其他方式,请让我们看到,你所做的一切,真的出自学术的目的,是想勘误,想讨论,而不是想炒作。 |
 |
51
songofhawk 2017-02-28 07:46:16 +08:00 via Android
我以为楼主的文章很好,内容也是客观诚恳的,给了大家一个讨论问题,澄清概念的机会。
人家也未必没有给阮一峰老师留言啊,揣测动机来否定不好。 |
 |
52
zollero 2017-02-28 07:53:09 +08:00 via iPhone
没有绝对的正确,只要 90%以上正确,能从中得到启发便足矣。
|
 |
53
murmur 2017-02-28 07:58:22 +08:00
最近一篇的错误不是狂吹 golang 么 还有 gos 一统江山
|
 |
54
ersic 2017-02-28 08:17:35 +08:00 via Android
如果楼主的标题是「阮一峰的这篇文章有哪些错误」,然后内容贴出这篇文章是没有任何问题的。但是你的标题,再加上主题的第一句「比如」,怪不得别人怀疑你的动机了。
|
 |
55
lovedebug 2017-02-28 08:18:55 +08:00
中文世界愿意和热爱分享的本来就不多
|
 |
56
berretta 2017-02-28 08:23:16 +08:00
阮一峰:编码之我见 楼主:阮一峰之编码之我见之我见 v2er :楼主之阮一峰之编码之我见之我见之我见
|
|
57
ersic 2017-02-28 08:46:29 +08:00
忍不住再多说一句,年前有人和阮撕过一次,是非曲直暂且不论,下面这段话我是非常认同的,也符合回应楼主的质疑。
http://ww1.sinaimg.cn/large/8c907d89gy1fd5w6m72b4j20gh0a8dhg |
 |
58
cszhiyue 2017-02-28 08:48:25 +08:00 via iPhone 不要歪楼,楼主关注点是用这个例子问出还有哪些是有错误的,我觉得挺好的。做个勘误
|
|
59
ersic 2017-02-28 09:11:34 +08:00 |
 |
60
liuxu 2017-02-28 09:16:10 +08:00
就第一句话,第一个“编码”是名词,第二个“编码”是谓词,第三个”编码“是名词,中文博大精深,这也是没办法的事。。
|
 |
61
taozhijiangscu 2017-02-28 09:24:40 +08:00
世上人无完人,博客有错误在所难免
随着自己的成长,肯定会发现自己之前的博文有疏漏或者不完整,保持着维持项目的态度,常常对自己的博客进行修正完善,是对阅读者的尊重和负责 所以,现在自己的博客也都申明别人除了标题+链接外,不允许全文转载,这样确保大家能看到的就确保是当前最新状态的文章 不过百度几乎没有在搜索中展示我的网站 (*Φ皿Φ*) |
 |
62
anthozoan77 2017-02-28 09:35:35 +08:00
这只是代表了别人十年前的理解和想法,何必呢?
|
 |
63
clino 2017-02-28 09:41:59 +08:00
"这句话读起来很拗口,有三个地方出现了「编码」二字。不知阮老师对「编码」的理解是什么?但可以肯定的是这三个「编码」在这句话里面不是同一个意思。"
你是一下你理解的意思都是什么? 我咋没看出来呢? 感觉都是一个意思啊. |
 |
64
taoxin167 2017-02-28 09:45:35 +08:00
从来否认自己短处,一昧放大别人错误
|
 |
65
Sh888 2017-02-28 09:46:56 +08:00
正确做法不应该是学好英语看白皮书么?
|
 |
66
fulvaz 2017-02-28 09:50:25 +08:00
一年前还是小白的我非常崇拜阮一峰老师, 因为我先学习的内容几乎都有阮一峰老师的身影, 直到我读了<如何变得有思想> 我觉得, 以后看任何人都要冷静
事实上任何人都不应该被当成权威, 这句话是我浪费三年的时间得到的教训 (我指另一件事情 |
 |
67
xiaonengshou 2017-02-28 09:57:30 +08:00
阮老师在技术上的段位并不是很高,参照他在蚂蚁的段位就可以了,但是他写的 es6 指南等等确实是很好地书籍,看一看很好,见仁见智吧,有时间的话就发个邮件给他呗,我想他肯定会回复了。
|
 |
68
peinhu 2017-02-28 10:03:09 +08:00
阮一峰说不上大牛但至少对待知识的态度是很好的,而且也乐于分享,挺实在的一个人。楼主不要太吹毛求疵了,人无完人,多一点包容吧,想想现在有多少人还愿意费时费力不收钱跟你分享知识?
|
|
69
21grams 2017-02-28 10:06:16 +08:00
中文互联网上,真正愿意写一些入门级的文章的人太少,更多的人只是热衷于写一些高大上的没多少人看的懂的文章,阮一峰能够花时间写这样的入门文章,我觉得功德无量。
|
 |
70
DinoStray 2017-02-28 10:21:50 +08:00
这样咬文嚼字大家谁也不敢写技术博客了
|
 |
71
stranbird 2017-02-28 10:22:16 +08:00 阮一峰最好的地方是一开始说的东西小白能看得懂,整理得也相对全面。即使有错误,也不妨碍小白进入那个领域,继续研究。
中文社区这样子的博主已经太少了,大多数搜出来只有解决一个特定问题的。比如你真的说搜 utf8mb4 那个,给小白讲只是在给他们增加认知上的负担。 我觉得一个良性的互联网知识生态应该是有很多阮老师这样的“小学老师”,也有很多深入研究某个领域的“大学教授”。 |
 |
72
jsq2627 2017-02-28 10:25:15 +08:00 |
 |
73
coderzheng 2017-02-28 10:27:18 +08:00
其实我想说一个问题,如果阮老师的博客在业界没有什么名气,估计说他的人就微乎其微吧。所以人怕成名猪怕壮,阮老师也是凡夫俗子,写的文章有点错误在所难免, LZ 不必较真。
|
 |
74
hqfzone 2017-02-28 10:38:32 +08:00
闲的
|
 |
75
xi2008wang 2017-02-28 10:42:06 +08:00
都是定义问题:
unicode 可以指单个字符的编码值(重点 值) 可以指上述所有这样字符的集合(重点 字符集) 可以是字符到编码的映射规则 (重点 对应规则) 所以说单说 unicode 就是耍流氓 |
 |
76
btjoker 2017-02-28 10:46:54 +08:00
吃饱没事干,啥事都要来批判
|
|
77
stabc 2017-02-28 10:48:04 +08:00 大海航行靠舵手,写程序靠阮老师启蒙!
LZ ,人民的眼睛是雪亮的,你妄图污蔑、诋毁、诽谤伟大导师阮老师,以及煽动、拱火、挑拨程序员内部矛盾的罪恶行径已经败露,你即使在附言中道歉也没用,反而更加说明了你是个无比阴险的投机分子。你现在要坦白交代,你到底什么目的?背后主使是谁?得到了什么好处? 你必将接受人民的审判,被永远的钉在历史的耻辱柱上!!!! |
 |
78
FrankHB 2017-02-28 10:54:05 +08:00
|
|
79
FrankHB 2017-02-28 10:55:45 +08:00
@coderzheng 作为读者,希望内容质量能和名气正相关,节约点时间。
作为懂行的那部分相关领域的读者,希望能正经科普少添乱。 |
 |
80
huson 2017-02-28 11:00:01 +08:00
虽然 ruan 老师的 博客帮助了很多新手
但是楼主只是指出了其中的错误 我觉得没什么不对呀 有错就改不就行了 扯什么名气啥的 |
 |
81
chmlai 2017-02-28 11:04:58 +08:00
在中文网路, 阮一峰挺难得的
|
 |
82
shyrock 2017-02-28 11:05:57 +08:00
第二个问题阮一峰说的是“如果”啊,你没看清就瞎喷。。。
|
 |
83
skywalker 2017-02-28 11:07:13 +08:00 阮一峰最令人佩服的是能用简明扼要的语言去解释问题,这在国内技术圈是难能可贵的。有没有错误?当然会有了,但是又有什么关系。想了解任何技术,靠一篇文章、一本书都是不够的,你想了解 Unicode ,把这个作为一个起点,在读其它文档时对概念有所了解,不就很好吗? 伍尔夫说,我们在读书时,第一遍要做作者的朋友,第二遍要做审判官。有错误没有关系,只要有价值就行。
看到回复里那些阴阳怪气的,徒增笑耳。 |
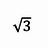
 |
85
comcuter 2017-02-28 11:07:53 +08:00
为什么要起这么大的一个标题, 我还以为是要把所有文章的常见错误都给挑出来呢
|
|
86
FrankHB 2017-02-28 11:09:36 +08:00
@vultr 首先找错误未必“花大量的时间”,内行可能一眼就注意了;而花时间告诉别人这里存在问题和“写几篇正确”作用类似,成本不同。同时没法要求有技术专长的人人都能高产赛母猪……
@DeutschXP 我有些好奇你如何揣测出“新人”“向上爬”。我在这里完全看不出这一点。 @ersic 太多人没注意到“个人笔记”的性质了。 @linxu 谓词(虽然也叫 predicate )看来不是你要说的意思…… @21grams 我觉得让人找不清楚门在哪里往哪边开是很不够意思的。 @stranbird 我经验的和你认为的正相反,大部分真·小白对这类内容来源是抱着跪舔的心思拜读的(其中的多数还不会说出来这种不长脸的事)。 |
|
87
DinoStray 2017-02-28 11:14:40 +08:00
|
|
88
clino 2017-02-28 11:17:58 +08:00
|
 |
89
zhidian 2017-02-28 11:22:42 +08:00
>>>
再来看阮老师说 Unicode 的第二个问题: [ 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0 ,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。] Unicode 并没有统一规定每个符号用三个或者四个字节表示。 Unicode 只规定了每个字符对应到唯一的代码值( code point ),代码值 从 0000 ~ 10FFFF 共 1114112 个值 ,真正存储的时候需要多少个字节是由具体的编码格式决定的。比如:字符 「 A 」用 UTF-8 的格式编码来存储就只占用 1 个字节,用 UTF-16 就占用 2 个字节,而用 UTF-32 存储就占用 4 个字节。 --- 阮老师说的是 [要是] unicode 这么设计的话,是多么浪费啊!你却认为阮老师说错了。所以你在逗我???你的槽点简直比他多一万倍好不好。 |
|
90
FrankHB 2017-02-28 11:25:52 +08:00
既然务求严谨,顺便纠正 LZ 的几个表述不清晰的地方(包括错误):
“其实 Unicode 是一个囊括了世界上所有字符的字符集,其中每一个字符都对应有唯一的编码值( code point ),然而它并不是一种什么编码格式,仅仅是字符集而已。 ” —— Unicode 的本义大概是如此,不过现在早就跑飞了。现在的 Unicode 很难单独抠出“字符”的概念和日常的字符讲清楚(这是我认为 Unicode 辣鸡的地方,且按下不表)。例如, emoji 姑且可以认为是“字符”,但带颜色和不带颜色的 emoji 指派不同的 code point 是什么鬼? “ UCS-2 是使用两个定长的字节来表示一个字符” ——编码 UCS-2 的是两个八元组(octet),不能和字节(byte)任意互换。 “而 UTF-16 是使用两个变长的字节” ——读起来难以言喻…… “之所以在 Windows 下有 Unicode 编码这样一种说法,其实是 Windows 的一种错误表示方法,它真正的编码类型是 UTF-16LE 编码。” ——因为历史原因,当年所谓的 Unicode 编码=UCS-2 ,因此也不全然是错误。反倒直接说 UTF-16 是有问题的。事实上, UTF-16 的普遍支持是 Windows 2000 加上去的(部分超出 BMP 字符的用户层机制如 WM_UNICHAR 在 Windows 7 之后才全面支持)。 “ Unicode 只规定了每个字符对应到唯一的代码值( code point ),代码值 从 0000 ~ 10FFFF 共 1114112 个值 ” ——历史上除了最开始的 16 位编码空间外,之后曾扩展到 32 位。限制 U+10FFFF 是 RFC 3629 时候的事。(顺便注意一下 UTF-8 的版本。) |
 |
91
sokis 2017-02-28 11:26:33 +08:00
跟阮一峰接触过,也听过他的培训,确实是个很有趣的人。。手动滑稽 :)
|
|
92
FrankHB 2017-02-28 11:30:30 +08:00
@zhidian 不巧,历史上 Unicode 和 ISO 10646 钦定的一些重要的方案如一开始的 16 位直接索引的编码和之后的 UTF-32/UCS-4 就是这样“浪费”的;退一步说,至少 UTF-8 发明之前就是这种状况。你的槽点又有几何呢……
|
 |
93
grzhan 2017-02-28 11:36:22 +08:00
本来看标题以为是个关于阮老师的勘误集中贴
自己以前也看了不少阮老师的文章所以点进来想看看到底是有哪些错误…… |
|
94
FrankHB 2017-02-28 11:39:18 +08:00 @DinoStray Java 语言一开始使用 UCS-2 , J2SE 5 开始使用 UTF-16 ,现在由 JLS 规范。 Java 的一些 API 支持 UTF-8 和 MUTF-8(modefied UTF-8)。 JVMS 规定 JVM 的实现需要用到 MUTF-8 表示特定的字符串。一些其它实现如 Dalvik dex 也使用 MUTF-8 。
|
|
95
onlyhot 2017-02-28 11:43:18 +08:00 via iPhone
真是中文圈特色了吧,就没几个人讨论内容 呵呵
|
 |
96
wyx 2017-02-28 12:17:43 +08:00
科普文有什么好挑错的...
|
 |
97
Aspx 2017-02-28 13:01:39 +08:00
阮一峰真正牛逼的是人家能坚持写博客这么多年。另外是人就会犯错,又不是谁没犯过错。
|
 |
98
jadecoder 2017-02-28 13:29:13 +08:00
「如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0 ,这对于存储来说是极大的浪费」
这么简单的一句话都读不懂,我觉得是楼主的问题 |
 |
99
xuelu520 2017-02-28 14:03:52 +08:00
发表时间:日期: 2007 年 10 月 28 日。
楼主能看出这么多错误,说明也是认真去看了,这篇文章的目的就达到了。 有错就改就是了。 |
 |
100
anoyafk 2017-02-28 14:25:05 +08:00
讨论内容就去阮一峰的博客评论
|